atmaCup#8参加記(pop-ketle版)
はじめに
こんにちは。お久しぶりです。
2020年12月4日(金)〜12月13日(日)に開催されたatmaCup#8に参加しました。
僕はatmaCupに出るのは2回目でした。
初めての時は忘れもしない#6 Sansan × atmaCup。
詳しく話していいのか忘れちゃったので、今回はさっとしか触れませんが(思い出したら感想書くかも)あの時受けた屈辱だけは忘れられず、何度も夢に見ました。
そう...初めてみるタイプのデータに何をしたらいいか何もわからず、ほぼ2週間何もできずに、それこそディスカッションで公開されたベースラインに毛を生やすことすらできずに、この人たち一体何をディスカッションしてるんだ?と自分の無力をひたすら味わい続けて、リーダボードのほぼ底辺で泣いたあの屈辱を。
その屈辱を返す時が、ついにやってきたのです。
今回は初心者向けと銘打たれており、初心者から中級者へ、一つ壁を越えるための避けられぬ壁だと強い気持ちを持って戦いに臨みました。
開会式
開会式は12/4 18:00、この時、僕は神妙な顔をしてPCと向き合い、開会式に向けて精神統一をしていた...
と、言いたいところですが、実際は7日に重要なプレゼンをしなくてはいけなかったので、7日の用事が終わるまではコンペはほとんどノータッチでした。
ちなみにコンペ開始直後に動きを見せずにじっと、さながら潜水艦のごとく様子を伺うこの戦法はサブマリン戦法と呼ばれ、人々を油断させて機を見て喉笛を喰らう戦法として古来から畏怖されてきました。参考文献
(なお、この間、僕はコンペのコードをほぼ書けなかったので別に戦略的な意味は全くありませんでした。)
プレゼン資料の細かいレイアウトの修正をしながら、開会式を見ました。コーヒーコンペがゲームの売上予測コンペに変わり、ゲーム好きな僕としては非常にテンションが上がりました。(コーヒーコンペも楽しみに待ってます。)
序盤(7日くらいまで)
実際はプレゼン資料はほぼ出来上がっていたので、コンペにガッツリ取り組んでも良かったのですが、僕は極度の対人恐怖症でプレゼンのことを考えると吐くレベルだったので、恐怖で頭が支配されていて深い考えを巡らす余裕がなかったため、簡単なベースラインだけサブミットして後はディスカッションを眺めていました。この時スコアは1.6969でした。(ちなみに評価指標はroot mean squared logarithmic error)
あまりコンペのコードを考える余裕はなかったので、ディスカッションを眺めていると、'Name'(ゲームのタイトル)から特徴量を得たい、といった旨のディスカッションが目につきました。
...気づいたらディスカッションを書いていました。Nameのembeddings表現から特徴量を得られないか検討 不安とは一体...(一応弁解しておくと、以前似たことをやったことがあったので、過去のコード資産からほぼコピペでかけるコードでした。)
(今回コンペの形式がopenだったぽいので、ディスカッションも貼れていいですね。atmaCupは日本語で良質なディスカッションから情報を得られるので、見れるものは一度覗いてみることをお勧めします。)
Nameのembeddings表現から特徴量を得られないか検討 について
せっかくなので、このディスカッションについて書いてみます。
本データには結構似たタイトルのゲームがありました。(というか全く同じものもかなりありました。別プラットフォームでの販売、リメイクなどなど)
個人的な感覚として、なんとなく似たゲームは似たタイトルになるよなと感じた点。また、同じシリーズのゲームのデータがあった点。これらを踏まえて、タイトルからゲームの傾向を掴めないかなーというのを、下記ディスカッションを眺めていて思いました。
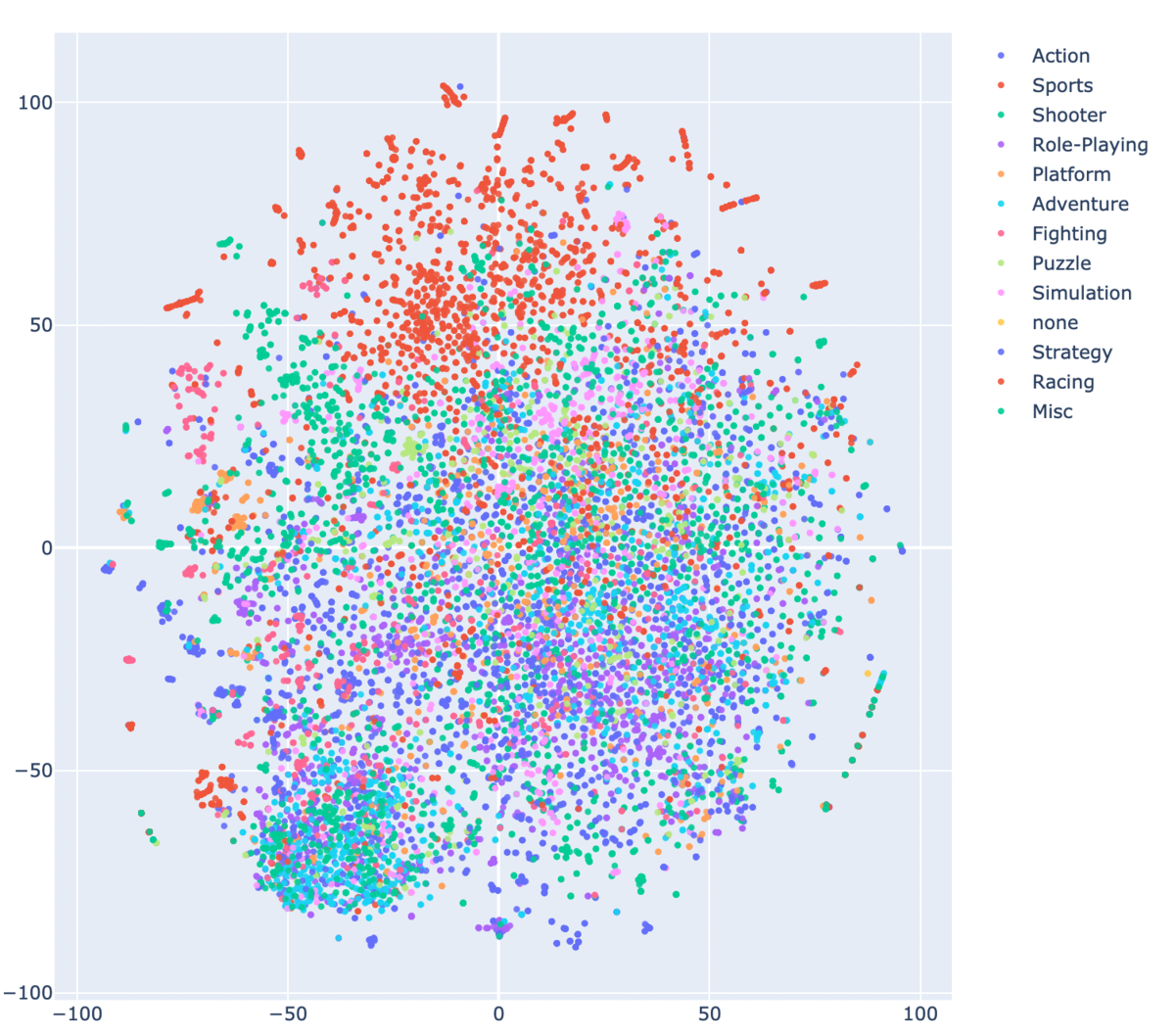
以上を踏まえて、Nameのembeddings表現(いわゆるベクトル表現)から傾向を得られないかということをやりました。 ディスカッションに書いてあるので繰り返しになりますが、流れとしては、以下のことを目的としたディスカッションでした。
Nameのembeddings表現をBERTを使って得る。
Nameのembeddings表現をtsneで2次元に次元削減する。
Plotlyで散布図として表示することで(ついでにジャンル別に色分けして表示することで)、何か情報を得る。
ご覧のように、スポーツなどは割と似たタイトルのものが固まっていてジャンルとして、うまいこと分けれるのではないかなという印象を持ちました。
t-SNEでの散布図 html
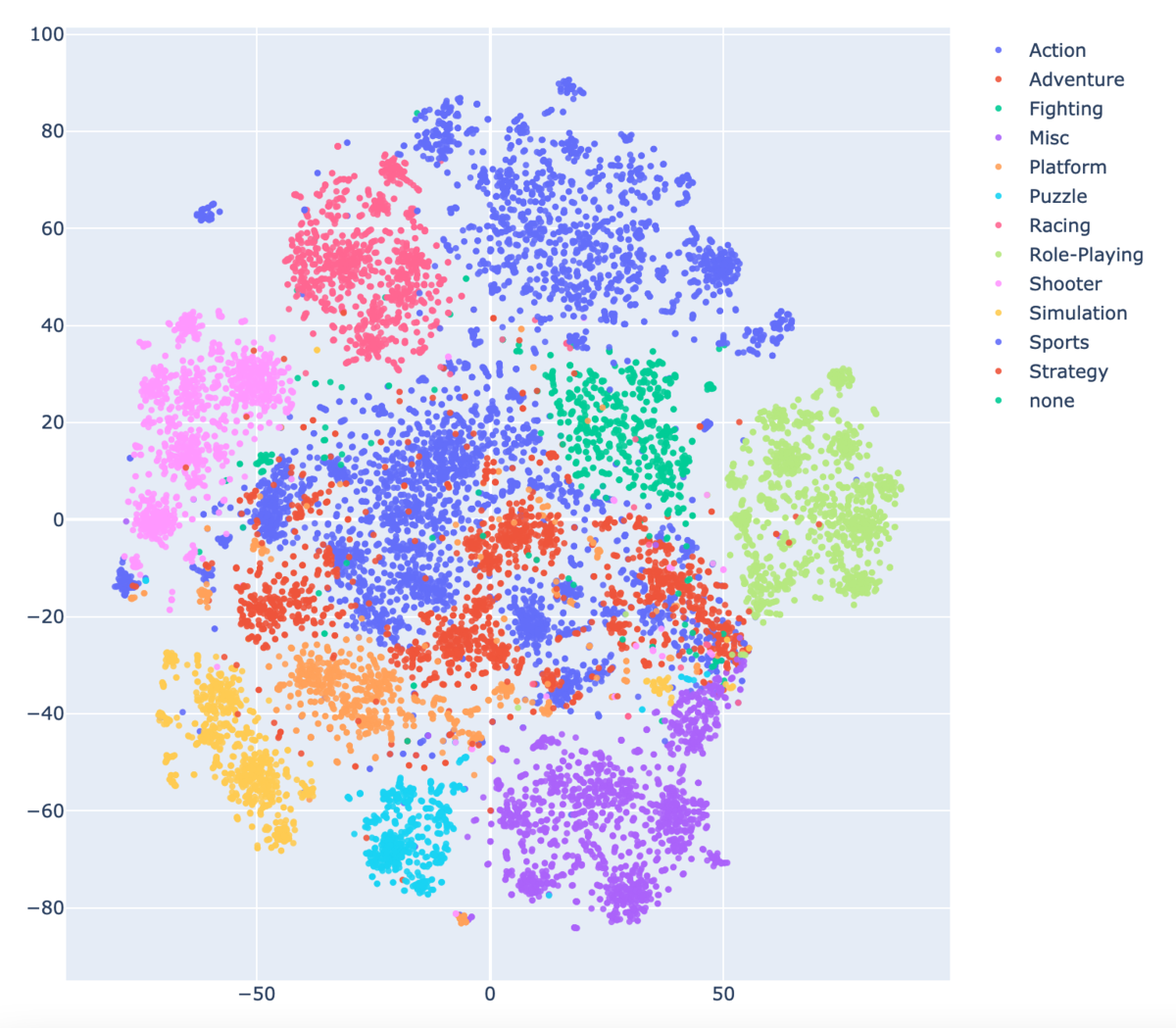
ちなみに、こっちはディスカッションには上げませんでしたが、Nameの前にGenreの情報を付け加えたもので得たEmbeddingsで作成した散布図はかなり綺麗にGenreごとに分かれました。
このことからタイトルからジャンルを推測はできそうだなという感想を持ちましたが、ジャンルの予測をしたい状況が生まれなかったので、これはそこまで役に立ちませんでした。(後にも書きますが、これら2つのEmbeddingsをt-SNEで得た二次元の情報はfeature importanceでそこそこ上位につけていたので、全く役に立ってないわけでは無いです。)
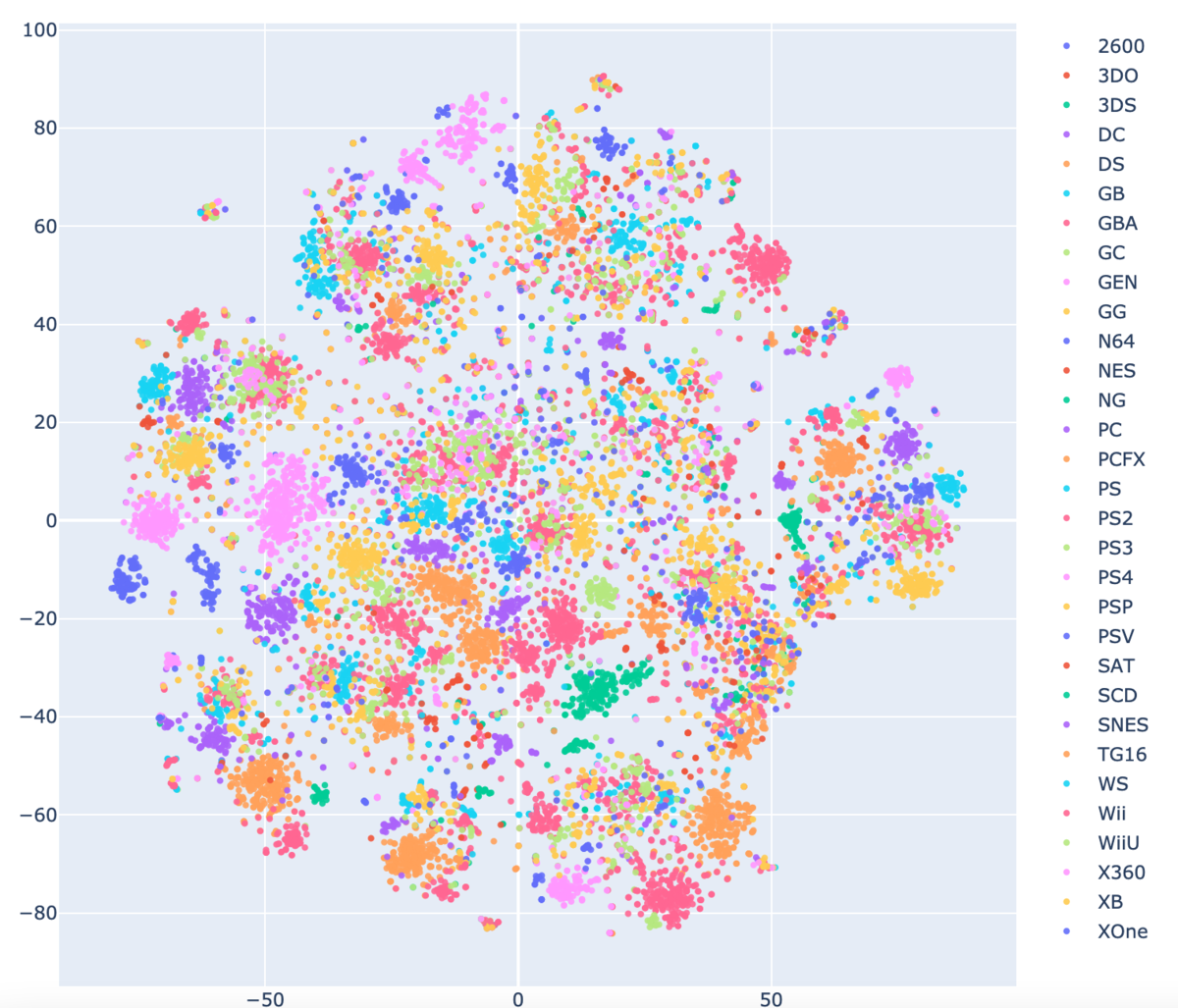
おまけですが、Platform+NameのEmbeddingsをt-SNEかけたものは、ここから情報を得るのちょっと難しいかなという感想を得ました。同タイトルでプラットフォーム変えて販売したりしてるのでそれはそう。
8日〜10日 0.9の壁
7日の重たい用事が終わったので、ここからはフルコミットで取り組みました。 一般的な特徴量を色々つくりました。
作った特徴量を大雑把に紹介
カウント/ラベル/ワンホット/ターゲット 各種エンコーディング
まぁ普通にそれなりに効いた。(ターゲットエンコーディングはそんなに効かなかった気も、一番カウントエンコーディングが効いてた印象)
Platform+Genreを文字列として結合してカウントエンコーディング
プラットフォームごとに流行りのジャンルとかありそうだなと思ってやった。効いたような効いてないような。
Platform+Genreを文字列として結合、追加でYearをビニングしたものも文字列として結合してカウントエンコーディング
プラットフォームごとに流行りのジャンルが年毎にありそうだなと思ってやった。そこそこ効いた。ちなみに5年単位でビニングした。
Name、Genre+Nameの2種のt-SNEの二次元ベクトル
Feature Importanceではそこそこ上位にいたけど、あんまり効いてなかったような...? 実際、Nameの特徴量が売り上げにそこまで効きそうな感じしないし。
User_Scoreのtbdのフラグ
User_Scoreにtbdという、おそらくTo Be Determined (現在未決定だが、将来決定する)を意味する文字列が、欠損値とは別に相当数あった ちなみに、対して効かなかった。
Platform・Genre・Ratingごとに各種売り上げ['EU_Sales','Global_Sales','JP_Sales','NA_Sales','Other_Sales','Global_Sales']の平均、最大、最小、合計を計算
無難に効いた気がする。ただ、ここら辺の情報を使うのはリークが怖かった。
PlatformのPublisher数、Developer数、Genre数、User_Count数をカウントしてplatformの人気度?的なものを考慮
そんなに効かなかったぽい。(feature importanceを見る限り)
Platformが発売された年度の作品かどうか
ローンチタイトルは売れるんじゃね?みたいなディスカッションがあったので、参考に追加。そんなに効かなかった。
発売してからの経過年数
発売してから時間が経つと、人気も少しずつ上がっていって(一般家庭に普及して)ピークを迎えたら、その後目減りしていくだろうなと考えて作成。結構効いた気がする。個人的に割と他の人は作らなかった特徴量として差別化になるのではないだろうかと思う。
User_Score x User_Countでユーザーがつけたスコアのサム
User_Scoreがかなりfeature importanceで上位につけていたので、これをもっと活かせないかと考えた。結果結構効いた(feature importance上は)。
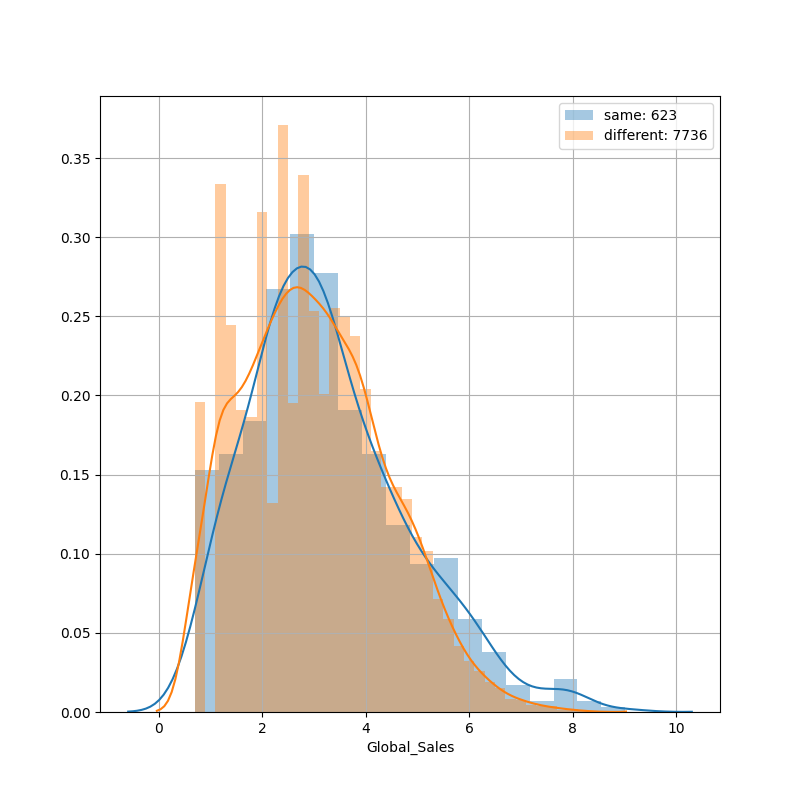
PublisherとDeveloperが同じか違うかのフラグ変数
パブとデベが一緒だと無難なゲームになりがちで、違う場合はデベが意欲作を出していて、売り上げがバラつくんじゃないかと予測した。trainのデータでしかないが、実際に同じだと安定した分布で、違うとばらついてる様子がみて取れると思う。ただ、feature importance上位には出てこなかった。ちょっと効いた気もするがそこまで効かなかった。
長々書いたけど、だいたい作成した特徴量はこんな感じ。
モデル
安定のLightgbmと、途中からcatboostを混ぜた。 ただ、catboostのターゲットエンコーディングは使わなかったので(処理を書くのがかなり面倒だった(効くのか自信がなかったし))、どこまで混ぜた意味があったか疑わしいものである。
ちなみにoptunaつかったんだけど、全く精度が上がらなかったので、初心者向け講座で使われてたパラメータをずっと使い続けてた。
ここまで
ここまでやって、なかなか0.9の壁を破れなかった。当時のTwitterからも苦戦している様子が窺える。何か壁を破る飛び道具が必要だなと考え始める。
ぐ、ぐぎぎぎぎぎ... pic.twitter.com/uy0Fi0cfWU
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月10日
Publisher == "Unknown" のデータに対する考察
何を思ったか、ディスカッションを立ち上げる。Publisher == "Unknown" のデータに対する考察
何か策は無いかと、データを眺めているとPublisher=="Unknown"のデータに明らかに、パブがUnknownではなさそうなデータがいくつか見つかった。意図的にPublisherをUnknownにして、trainとtestでPublisherが被らないようにしている可能性があるんじゃ無いかなーと思ってディスカッションを立ち上げてみた。(最初は、僕の好きなSubnauticaというゲームが"Unknown Worlds Entertainment"開発なので、聞いたことないけどそんなパブリッシャーもあるんだなーとあんまり気にしてなかった)
Publisher=="Unknown"の例:
- "Nintendo Puzzle Collection"
- "Mega Man X Collection"
- "Persona 5"
- "Final Fantasy Type-0"
- "Afrika"
コメントでもいただいていたが、ここら辺外部データの使用にもなりそうな気もしていたので、どうかなーと思ったが、ギリギリセウトだろうと思ってディスカッションにしてみた。というか一人で抱えておいて、後からダメですと言われる方がつらいと考えた。
(参加してなくてあまり事情を知らない人向けに書くと、据え置きかどうかも外部データ扱いでフラグ変数に与えるのは無しでと言われていたというのもあったりしたので、ここら辺割とかなりグレーで運営を困らせていた可能性はある。すみませんでした。)
後でもちょっと述べるけど、ここら辺の特徴量は僕は使ってない。(いや、UnknownをNaNにするのを試したりしたので使ったといえば使ったかな。)コメントでも書いたけど、Publisherを予測なんてできないだろうし、運営の意図が見えてちょっと面白いかなくらいの気持ちでディスカッションを書いた。
神ディスカッションとの出会い
最終的にベストディスカッションに輝いた[update]atma8の進め方を考えてみた(ドメイン特徴量, Publisherの扱い方など)をよく読んでみると中に、Publisher、Developerにpivot_tableを作ってPCAをして特徴量を作成するといった旨のことが書いてある。これを使うことで、0.9の壁を破ることができた。本当にありがとうございます。
やったー、やっと0.9の壁を破った!
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月11日
Nice Hard Work ✒ 現在の順位は 22位です. https://t.co/Hq1WFLId3S #atmaCup pic.twitter.com/Wnl3msXyGo
ただ、このPCAで一気にスコアが伸びた理由について正直いまだに腹落ちしていない。コメントも見てみたけど、いまいち納得できていない。ここは勉強が足りていない部分である。
瞬間最大風速
この後、 発売回数(プラットフォームで分散の可能性)、別の年に発売されたかどうか(リメイクされたかどうか)などの特徴量を加えて、瞬間最大風速、敢闘賞で12位、全体で14位を記録する。
ちなみに、この後は色々やってもスコアが上がらず、相対的にどんどん落ちていく...
刻んでゆく
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月11日
Nice Hard Work ✒ 現在の順位は 12位です. https://t.co/Hq1WFLId3S #atmaCup pic.twitter.com/AMeADOC3x7
さいご
最終的に敢闘賞で26位、全体で30位になった。4位分シェイクダウンしてしまったのだが、ベストサブをきちんと選べているので、単純に他の人が上手だったということになる。 目標の一つだったTOP 15%には入ることができたので、非常に嬉しく思っている。その一方でもう一つの大目標、入賞して物理メダルをもらうは達成できなかったので、その点は非常に残念ではある。しかし、これで初心者の壁を少しは越えることができたのではないかなと思っている。どうかな?みんな?
#6 Sansan × atmaCupで何もできず己の無力に泣いたあの時の雪辱は返したぞ、あの時の僕よ。
今回のコンペに関して
今回のコンペではいくつかの流れがあったと思う。それに対して、ちょっと書いてみる。
trainとtestのPublsher分布の違い
本コンペではtrainとtestのPublsher分布が完全に分かれていて、そのためバリデーションをどうするかという点が結構争点になったと思う。(これもあってPublisher=="Unknown"のディスカッションを上げた。結構コメントで盛り上がってくれて嬉しかった。)
正直、正解は今でもよくわかっていないのだが、僕はPublisherをStratifiedKFoldすることで、バリデーションごとにPublisherでの差が生まれないようにという意図を持って進めていた。ある程度相関は取れていたのだが、完全にリンクしているとは言えなかった。
Cross Validationについて(CV:0.796, LB:0.8828 → CV:0.871, LB:0.8823)
一度上記のシリーズで分割する方法も試したのだが、目立った改善がみられなかったので今まで使っていた安全牌に戻ってしまった。
結局、どうするのが上手いバリデーションだったのかは上位の回答をみても明確な答えはないように思える。
シリーズの特定
Nameのembeddings表現のディスカッションを書いておきながら、自分はあまりシリーズの特定には積極的ではなかった。ディスカッションの流れを見るに多くの人がこれに取り組んでn-gram使ったり、レーベンシュタイン距離を使ったり、単語の出現回数使ったりと色々工夫をしていたようだが、個人的にはシリーズの特定が売り上げにそこまでつながる気はしなかった。
というよりうまくシリーズの特定ができるのかというのが疑問だった。例えば例をあげると、"LEGO Harry Potter: Years 5-7"を"LEGO"シリーズに入れるか、"LEGO Harry Potter"シリーズに入れるかの判断は難しい。(ちなみにレゴハリーポッターはクソゲーです。)このように、シリーズをどう区切るかは人でも難しいところがある。
みんな、この点工夫して頑張っていたようだが、自分はNameのembeddings表現のt-SNEだけ突っ込んでシリーズ特定による特徴量は使わないことにした。 どこまで差が出たかは、分からないがどうだっただろうか。
リーク
このコンペを語る上で、これは避けられないだろう。ある段階から、1位のスコアが飛び抜けてよくなり、ワザップにatmaCupの裏技が乗ってるなど話題(ネタ)になった。
リーク内容の詳細については1位の人のディスカッションを読んでください。1st place solution
言われてみると確かに最初にデータをみた時に、Year_of_Releaseで綺麗に並んでるなーとか思った覚えがあるんだよなー、違和感に敏感になれる人間になりたいですね。
感想
どこかでみましたが、テーブルデータだと思ったら、自然言語処理だったと思ったら、時系列データだったというのが、このコンペを表している気がします。参加者ごとのレベル別にいろんな角度から見ることのできるデータでかなり面白いコンペだったと思います。
本当に初心者向けのコンペとして非常に出来が良く、初心者にはタイタニックよりもこれをお勧めしたいと感じるくらい非常に良かったと思います。最高でした!(次はコーヒーでバトル!(コーヒーじゃなくても次回も楽しみに待ってます。))
また、今回は2つディスカッションを上げることができて、意見交換できたり、Upvoteもらったりと非常に楽しくやれた。第二回での初心者向け講座で良いディスカッションがあると紹介してもらえたりと非常に嬉しかった。楽しい思い出がいっぱいですね。
最後に、1位のmagic featureでのlate sub
1位のmagic feature late sub部 pic.twitter.com/qB9eNGG4AG
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月15日
全く整備してませんが一応Githubのリポジトリ貼っておきます。スターくれたら泣いて喜びます。(一度もらう経験をしてみたい。) GitHub - pop-ketle/atmacup8