atmaCup#10参加記(pop-ketle版)
はじめに
ハローワールド、pop-ketleです。
どうやら、前回のatmaCup#8から1つもブログ記事書いてないんですね。 僕の頭の中では色々コンペ出てブログで参加記を書いたつもりだったのですが、どうやら妄想だったようです。近いうちにちゃんと書きたいですね。
今回はタイトルの通り、atmaCup#10の参加記です。できるだけ早いうちに書こうと思っていましたが、結局遅れて旬を逃した感じになっています。
概要
今回のatmaCupは「美術作品の属性情報から、ユーザーがどの作品を良いと思うか、を予測する問題」でした。評価指標はRMSLE。
僕の結果は、チーム 525中、Public/Private両方とも62位で全くshakeはなしでした。 CVとLBが割と綺麗に相関しているイメージだったので、スコア的にはshakeしないだろうけど、結構LBが密だったので順位の上下はあるだろうなと思っていたのですがshakeしませんでした。
atmaCup#9でもshakeしなかったので、shakeしない才能があるのかもしれません(student cup 2020の話はNG)
一応TOP15%には入れたのですが、正直個人的には今ひとつな順位で、かなり不完全燃焼感あります。 まぁ、学んだものはたくさんあったのでよし。
今回、本当にスコアが密で、サブして寝て起きると順位がガッツリ落とされているみたいな激しい戦いでした。 最初の想定では、結構ガッツリatmaCupのために時間取れる予定だったのですが、なんか引っ越しの準備とかがあって思っていた以上に時間がなくて厳しかったです。
初心者歓迎ということで思いっきり歓迎(LBでボコられる)をされました。
atmaCupの"初心者歓迎"は「ボコボコにしてやるから、初心者はかかってこいよ」の意味である(嘘です) #atmaCup
— KEN(pop-ketle) (@ken7272popqjim) 2021年3月12日
そういったわけで、隙間時間にディスカッションの実装をパクって魔改造するぐらいしかできず、自分なりの工夫とかができなかったところが、スコアに如実にあらわれているかなと言った感じです。
働きながら参加している人がたくさんいる以上、言い訳でしかないんですが。 働きながら参加してる人には頭が上がりませんね。
序盤
コンペ開催前に投稿されたTabNetについてのディスカッションにビビり散らかしました。何がやばいかって、コンペまだ始まってないんですよね。戦いはコンペが始まる前からもうすでに始まっているんだということを分からさせられました。
このディスカッションの投稿と共に戦いの火蓋が切られたと言っても過言ではありません。(そうか?)
(Linkのこっちの記事もかなり良さそう)TabNetとは一体何者なのか?
TabNet、僕はあんまり知らないのですが(というかいきなり名前だけ見るようになって、どこで出てきたあれなのか全く知らないのですが、なんかのコンペで強かったんですかね?)TabNetについて日本語でここまで、まとまっている記事はあまりないと思うので、この記事はもっと広く知られるべきだと思います。
今回のタスクについて
ところで、今回のタスクの「美術作品の属性情報から、ユーザーがどの作品を良いと思うか、を予測する問題」ってかなり面白いですよね。ともすれば、個々人の感性によって大きく評価が変わりそうな美術作品の評価を予測して、スコアをつけるという、人じゃないと理解できないような、言語化しにくいものを機械に予測させるというのは、かなり面白いなと僕は思っています。
美的感覚の一般化ってできるもんなんですかね?うーん、面白いですね。
僕は別に芸術・絵画の専門家ではないので、これから割と適当言いますが、美的感覚って点で存在しているものではなくて、ある種のコンテキストの中で存在するものなんですよね。
絵は描かれただけではダメで、絵に対して解釈や評価、つまり、見る人が必要なんです。 そうした絵に対しての解釈や評価が重ねられて、重ねられて、積もり積もったものが絵の重みになるんですね。
つまるところ、その絵が描かれた背景や、有名な絵だというのを知っているからこそ、すごい絵なんだと判断でき、面白さ・美的感覚を共有できるわけです。
それを機械に学習させるというのは、やはりかなりチャレンジングな問題だと思っています。
それっぽく聞こえましたか?だとしたら幸いです。(冗談めかして書きましたが、割と本気で思っています、とだけは付け加えておきます。)
中盤
このコンペのちょい前に、atmaCupの猛者のpaoさんが短期間コンペの戦い方というLT?プレゼンをしてくれました。そのため、今回のコンペでは費用対効果というものを少し意識していました。 speakerdeck.com
と言っても時間かかりそうなのは後回しにする、とかどれくらい効きそうかを意識するとかの普通の取り組みですが。
具体例を挙げるとBERT系は結構チューニングとか真剣にやりだすと無限に時間が溶けるのを知っていたので、今回はサクッと試しやすいTF-IDFやw2vでの処理を基本にテストを回して、BERTは後回しにするなどしていました。
ただまぁ、今回データセットが小さめだったので、結局BERTも言うほど時間かからなかったのですが...
BERTはあんまりパラメータいじらず適当に特徴量作って、あんまり効かないなーとかやっていたところ、他の人は結構効いていたらしいので、少し失敗点ですね。
やはり、なんだかんだ現状はNLPはBERT最強な気がします。
取り組み
色特徴量
個人的な感覚として、色の特徴量はなんとなく効かない気がしていたのであまり触りませんでした。
object_idごとにaggregationして、下記特徴量を加えました。
- ratioのmax、minを計算
- RGB, HSVごとに'min'、'max'、'mean'、'std'、'var'、'max-min'
- 代表色による特徴量を参考にratioが最大のRGB、HSV、平均のRGB、HSV
若干効きました。
パレットの可視化 こちらのディスカッションをみて、意外と色とライクに傾向が見えてるみたいで逆に驚いたのですが、実際色の特徴量はどこまで効いたのでしょうね?
copastaさんの [Public 3rd/Private 1st] solution では、色で行列を作って、固有値を作って計算するところまでやって、それなりに効いたようですが、ここまでやらないと効かなかった感じなんでしょうか?
作家の情報
maker、principal_maker、principal_maker_occupationの情報を紐づけて単純に加えました。
今思い返してみるとここはもうちょっと深掘りしたかったなぁというところ。
作品のタイプ
作品のタイプを 複数対応しているテーブルデータを結合してみる(material.csv) こちらを参考にしながらくっつけました。
object_type=paintings がかなりFeature Importance上で上位に来ていたので、絵画はライクが貰いやすいのかなーとか考えていました。
historical_person
作品にhistorical_personが写っているかどうかのフラグと、その人数の特徴量を加えました。
作れるから作ってみたと言う感じで効いた気はしないです。
technique
作品のtechniqueをクロス集計表に成型してマージしました。
CVが落ちたのでやめました。
production_place
production_placeと、 geopyを使ってproduction_placeを地名→国名に変換する を参考に国名に変換したものをクロス集計表に成型してマージしました。
特に効いた感じはしなかったかなと言う感じ。
materials
materialの取り扱い こちらを参考に、materials をある程度まとめて数を減らした上で結合しました。
後述するw2vの埋め込みの際も、まとめないものと、まとめたもの両方作ってみても良かったかもしれない。
w2vを使って、系列を文章として埋め込み
これは以前見かけてから、ずっと試してみたかった手法で、今回、Arai-sanのわかりやすいディスカッションのおかげで、あまり苦労せずに実装できたのですごく感謝しています。 Word2Vecを使ってmaterial, technique, object_collectionなどを特徴ベクトル化する
Feature Importance上もかなり効いており、私の主戦力でした。
material、technique、object_collectionだけでもかなり効いたので、自分はここを深掘りして、principal_makerやhistorical_personなど、目につくものを手当たり次第くっつけてw2vで埋め込みました。
年代
ドメイン知識(西洋絵画とオランダの画家) このディスカッションのドメイン知識の話が面白かったので、年代を時期と世紀で分けられるように適当にビニングしてみました。
結構期待していたのですが、あんまり効かなかったです。
収集に際して資金提供などを行った情報があるかどうか
収集に際して資金提供などを行った情報、acquisition_credit_lineがあるかどうかについてフラグを立てました。
期待より効いたイメージ。(とはいえ、特徴量の少ない初めのうちから加えてたために、Feature Importanceが高かったように見えてただけかもしれない。実際、特徴量が増えてきた後半はFeature Importanceの彼方に流されていった。)
著者について
- 著者がデータセット中に何回出てくるか
よく分からない、特に効いてはなさそう。
- 著者ごとに何種類の sub_title を持っているか
終了後に落ち着いてみると、なんでsub_titleの数にしたのかよく分からない。永遠の謎。
- 著者ごとにデータセットに存在する作品の年度の最小・最大・平均
結構効いた。
テキスト
テキストのカラム、['principal_maker','principal_or_first_maker','title','description','sub_title','long_title','more_title']に対して、処理を行った。
まず、一般的な特徴量。コードで書いた方がわかりやすい気がするので、コードで記述。
# text の基本的な情報をgetする関数
def basic_text_features_transformer(input_df, column, cleansing_hero=None, name=''):
input_df[column] = input_df[column].astype(str)
_df = pd.DataFrame()
_df[column + name + '_num_chars'] = input_df[column].apply(len)
_df[column + name + '_num_exclamation_marks'] = input_df[column].apply(lambda x: x.count('!'))
_df[column + name + '_num_question_marks'] = input_df[column].apply(lambda x: x.count('?'))
_df[column + name + '_num_punctuation'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '.,;:'))
_df[column + name + '_num_symbols'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '*&$%'))
_df[column + name + '_num_words'] = input_df[column].apply(lambda x: len(x.split()))
_df[column + name + '_num_unique_words'] = input_df[column].apply(lambda x: len(set(w for w in x.split())))
_df[column + name + '_words_vs_unique'] = _df[column + name + '_num_unique_words'] / _df[column + name + '_num_words']
_df[column + name + '_words_vs_chars'] = _df[column + name + '_num_words'] / _df[column + name + '_num_chars']
return _df
(これよく見たら、cleansing_hero(textheroのテキスト処理パイプライン)使ってないですね。バグを発見してしまった...)
次に、CountVectorizerとTfidfVectorizerでベクトル化したものを、TruncatedSVDで64次元に落として、特徴量として加えた。
w2vで64次元に落としたものも加えた。
両者とも、結構効いた。
ちなみに下記のtextheroを使ったテキスト処理をしたら結構LBが上がった。今回はテキストの前処理が効果的だったようである。
# 英語とオランダ語を stopword として指定
custom_stopwords = nltk.corpus.stopwords.words('dutch') + nltk.corpus.stopwords.words('english')
def cleansing_hero_only_text(input_df, text_col):
## get only text (remove html tags, punctuation & digits)
custom_pipeline = [
hero.preprocessing.fillna,
hero.preprocessing.remove_html_tags,
hero.preprocessing.lowercase,
hero.preprocessing.remove_digits,
hero.preprocessing.remove_punctuation,
hero.preprocessing.remove_diacritics,
hero.preprocessing.remove_stopwords,
hero.preprocessing.remove_whitespace,
hero.preprocessing.stem,
lambda x: hero.preprocessing.remove_stopwords(x, stopwords=custom_stopwords)
]
texts = hero.clean(input_df[text_col], custom_pipeline)
return texts
BERT
['title', 'description', 'long_title']に対して、 後述の言語判定を行なった後に、言語別に英語、オランダ語、その他でそれぞれ対応するモデルを使って学習させて得たEmbeddingsを、TruncatedSVDを使って128次元に削減したものを特徴量として加えた。
自分の場合、今回の使い方ではBERTはあまり効かず、w2v、tfidfを使ったものの方がよく効いた。
ただ、ここはすごく反省点で、 2位のもーぐりさんのように最初に英語に変換してしまってから、BERT使った方がよかったなと反省した。(おそらく英語の方がコーパスの質、量がいいので)
また、言語別に対応するモデルを使おうと考えていたからなのか、['title', 'description', 'long_title']に対してしかBERTを使わなかったのがかなり間抜けすぎる。もっと使えるテキストがあるのに...
当時の自分をビンタしたい。
言語の判定
['title', 'description', 'long_title']に対して、 タイトルの言語判定特徴 このディスカッションを参考に言語判定を行った。
テキストの特徴量を加えたら、Feature Importanceの彼方に流されていったが、序盤はFeature Importanceの上位にいたので結構効いていたと思われる。
サイズ
sub_titleから作品のサイズを抽出して単位をmmに統一する このディスカッションを参考にサイズを抜き出しました。
gotoさんの講座2 [講座#2] EDA・モデルの改善 とかで、sub_titleの長さが特徴量の上位に来ていました。 これは基本的に作品の大きさを表すもので、この長さが長いと言うことはそれだけ作品が大きい、もしくは立体的、と言うことになります。
そこで、1.0で穴埋めをした上で、h*w、h*w*t、h*w*t*dをそれぞれ計算して、作品の大きさを表す特徴量を作成しました。これは結構効きました。
各種エンコーディング
適当にラベルエンコーディング、カウントエンコーディング、ターゲットエンコーディングをしました。
今回特にターゲットエンコーディングが結構効きました。
モデリング
最初はLightgbmでテストをして進めて、コンペ後半でLightgbmとCatboostの出力をRidgeスタッキングするいつものムーブをしました。 likesに対して、StratifiedKFold(n_splits=5)です。
そろそろ手札にMLP系のモデルを仕込みたいです。
あまりいい順位でもなかったので、パラメータチューニングより他のもっと本質的なとこだろということで、パラメータチューニングせず、LGBMRegressorに対してだけ下記のいつものパラメータを与えました。 ラーニングレートぐらいはいじってみてもよかったかな。
lgbm_params = {
'objective': 'rmse', # 目的関数. これの意味で最小となるようなパラメータを探します.
'learning_rate': 0.1, # 学習率. 小さいほどなめらかな決定境界が作られて性能向上に繋がる場合が多いです、がそれだけ木を作るため学習に時間がかかります
'reg_lambda': 1., # L2 Reguralization
'reg_alpha': .1, # こちらは L1
'max_depth': 6, # 木の深さ. 深い木を許容するほどより複雑な交互作用を考慮するようになります
'n_estimators': 10000, # 木の最大数. early_stopping という枠組みで木の数は制御されるようにしていますのでとても大きい値を指定しておきます.
'colsample_bytree': 0.5, # 木を作る際に考慮する特徴量の割合. 1以下を指定すると特徴をランダムに欠落させます。小さくすることで, まんべんなく特徴を使うという効果があります.
# bagging の頻度と割合
'subsample_freq': 3,
'subsample': .9,
'importance_type': 'gain', # 特徴重要度計算のロジック(後述)
'random_state': RANDOM_SEED,
}
選択した2つのモデルは下のような結果となりました。
CV: 1.00752、 Public: 0.9861、Private: 1.0042
CV: 1.00704、 Public: 0.9821、Private: 1.0038
選択した中でベストなモデルのFeature Importanceはこんな感じ(どっかバグらせて箱ひげ図になってないけど許して)
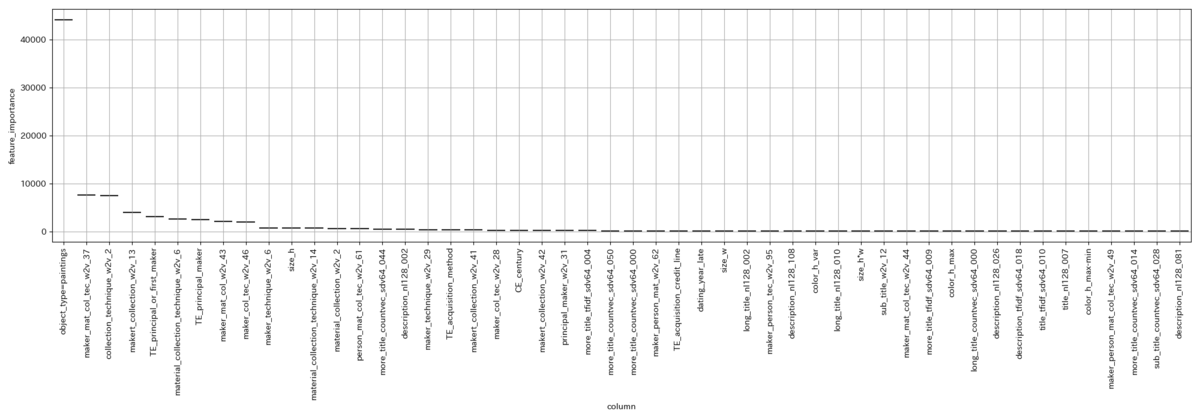
持ってたベストのサブミッションは、
CV: 0.99648、Public: 0.9892、Private: 1.0016
でした。
LBを見すぎて、Trust CVの基本を忘れたのは残念なところですかね。そこまで大きな差ではないですが。
Feature Importanceはこんな感じ。

おわりに
改めてまとめてみると、本当にディスカッションの後追いしかしてないですね...
ほんとは自分でディスカッション投稿もしたかったのですが、実装速度を出せなかったというのが正直なところです。 simpletransformersを使ったBERTによるEmbeddings抽出とか書こうと思えば書けたんだけどな...
Embeddingsをt-SNEとかで可視化みたいなのもやりたかったんだけど、ディスカッション書く時間的余裕と速度を出せませんでした。
コンペでは実装速度も大切ですね、特にディスカッションは。
ところで、今回上位陣でpseudo labelを使っている人がいた覚えがあるのですが、pseudo labelを試そうか考慮に入れるスコアの基準とかって、みなさん持っているのでしょうか? 自分の基準だと今回、pseudo labelを試そうとは全く思わなかったのですが、なんかポイントというか勘所というかあるんですかね?pseudo label、何度か他コンペでも試してるんですけど、なかなか効かないんですよね。気になります。
今回のコンペは色々データを見れて楽しかったです。学びもかなりあり(特にw2vの埋め込み)、思う存分歓迎していただきました、もう僕のライフは0です。
ただ、少し今後に対して不安も持ちました(今後はさらにコンペに割ける時間が減るであろうため)。社会人参加者の方マジ、リスペクトっす。
そういえば、反省点として今回のコンペでは、チームも組みたかったんですよね。
短期間コンペだと早めにチームを組んでおきたいところなのですが、勇気がなくて自分からチームマージを言い出せなかったり、思ったよりコンペに割ける時間がなくて相手に迷惑かもとか考えたりして、チーム組みたいと言い出せなかったのを強く反省しています。
ということで、正直今回のコンペはかなり不完全燃焼ですが、これが現状の自分の実力ということで真摯に受け止めます。これで今回のatmaCup参加記を終わろうと思います。
早く環境を落ち着けたいですね。コンペもできる限り出たいし、出るつもりですが、しばらく資格の勉強をそろそろ真剣に始めないといけないとかがあったりして、少し落ち着いて地力を貯める時期かもしれませんね。
なんか色々自分に足りないものが見えて、少し気疲れしてしまいますね。 正直、仕事も面白くなさそうだし、しばらく耐える時期になりそうです。はぁ...
最後に特に整備してませんが、Githubのリポジトリを公開します。例によってスターもらえたら私の励みになります。
ディスカッションでも実験管理のやり方について少し話が出ていましたが、私はあまりファイルを増やしたくないので、一つのファイルを書き足しながら進めてsubごとにcommitして、メッセージにメインで変更を加えたファイル名とCV、public LBのスコアを書く方式に現在はしています。参考にでもどうぞ。
ちなみに、もう少し期間が長いコンペの場合はNotionを併用して情報をまとめています。(実際はNotionあまり上手く使えてないけど)
github.com