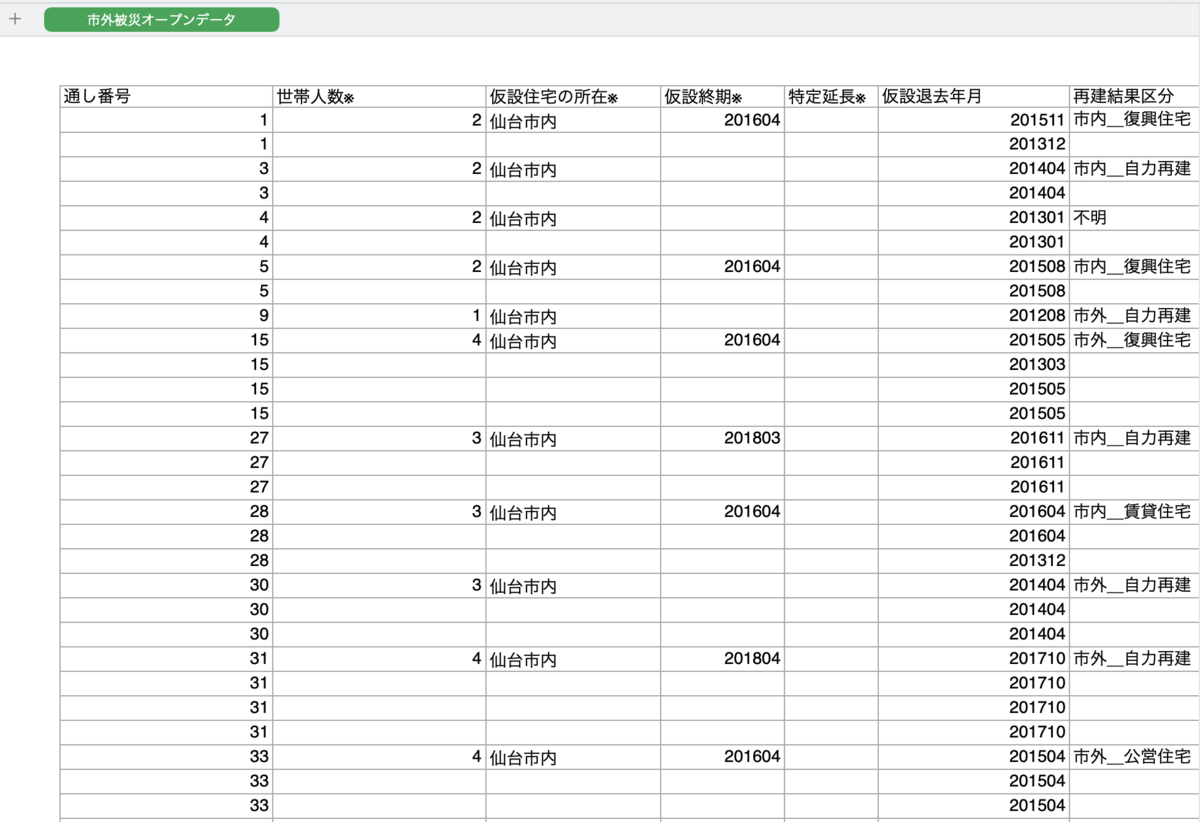
結論
チームマージはいいぞ
はじめに
ハローワールド、pop-ketleです。
期間空いてしまいましたが、ProbSpace 論文の被引用数予測コンペ参加記です。
参加ユーザー数: 168人中、Public: 5位 Privete: 4位でした。
概要
prob.space
「コンペティション概要」「背景課題・目的」「本コンペティションの特徴」を
コンペサイトから引用します。
コンペティション概要
本コンペでは、論文投稿サイト(プレ・プリントサーバー)の公開情報を用いて、
被引用数の予測モデル開発にチャレンジいただきます。
背景課題・目的
「論文の被引用数」とは、その研究論文が他の論文で引用された回数を示す数値であり、
被引用数が多いほど重要性の高い研究とみなされやすいことから、
査読論文の本数、掲載ジャーナル・カンファレンスの影響力 等と並び、
研究功績を評価する一指標として用いられています。
そこで本コンペにおいてはタイトル・アブストラクトへの言葉選び、ジャーナル・カンファレンスの選択がどれだけ引用数に影響するか考察したいと思います。
研究者・学生の皆さまにとって、論文執筆や研究テーマを選ぶ上でのインサイトとなれば幸いです。
本コンペティションの特徴
今回のコンペでは、学習データの一部に目的変数(被引用数)が含まれておらず、
代わりにDigital Object Identifier(DOI)により計算された低精度被引用数が代替変数として付与されています。
現実世界の問題においては必ずしも充分な量の教師データを用意できるとは限らず、
そのような場合においては弱教師あり学習が1つの有効な手段となります。
本コンペを通して弱教師ありにおけるモデル開発に親しんでいただければ幸いです。
コンペ概要について所感
個人的にかなり面白いタスクだなと感じていて、結構初期の方から参加してました。思うほど参加者が増えなかったのが不思議です。
また、今回のコンペでは弱教師あり学習に親しんで欲しいということで、DOIから算出された低精度被引用数(doi_cites)という、いわば弱目的変数みたいなものがあるのが特徴的でした。
ただ、いくつかソリューションを拝見させていただきましたが、結局あんまり弱教師あり学習ならではのソリューションみたいなものはなかった気がしています。
自身の取り組み
最初に断っておくと、僕自身のモデルはPublic:0.496693、Private:0.497997と本来なら4位という栄光に浴することのできるスコアではありませんでした。
チームメイトの人には感謝しかありません。アンサンブルでスコアが結構上がった印象があるので、その点で多少なりともチームのモデルの多様性に寄与できていたら嬉しいなという感じです。
ただ、特徴量部分では、他の人と比べてそこまで差が出る足りない特徴量があったか?という感想は持っていて、何がスコアに差が出ていたのか正直今でもよくわからないなという印象は持っています。 (差分学習はやっていなかったので、これが大きな違いになっていたというのはあり得る。)
大きな差が出る特徴量はなくて、小さなところが積もり積もっての結果なのかな?と今は考えています。(最後の方で一度特徴量を始めから作り直したのですが、見返すとそこでいくつか作成し忘れた特徴量があったので。)
序盤・中盤
弱教師あり学習が特徴らしい?コンペということで、「よし!弱教師ありぽいことするぞ!!」と
目的変数のcitesがないデータに対して、まずcitesを予測するモデルを作成し、trainデータのcitesの欠損値を埋めることで、使用可能なデータを増やす(いわゆるpseudo labeling的な)ことを取り組みとしてここしばらく試していました。
ただ、これはcv:0.245859、pub:0.501828 とあんまりうまくいきませんでした。(doi_citesを説明変数に入れてるので過学習してる)
ここら辺の取り組みは下記ディスカッションでも少し話しています。
論文の被引用数予測 | ProbSpace
この時の段階では、この「citesとかなり高い相関を持っているdoi_citesがどうやって作成されたものなのか」について考えをめぐらせていましたが、結局よくわからないまま終わってしまいました。
終盤 チームマージ前
Publicで0.5が切れなくてうだうだしていたので、誰かチームマージして0.5を切るワザップを教えてくださいと泣きつきました。大体コンペ終了の1週間前ですかね。
結果として優秀なチームメイトに恵まれ、3人でチームを結成することができました。
メモが残っていたので、
この時点での僕のソロでのベストスコアのモデルをさっくり紹介しておきます。
cv: 0.4946567032659036 pub: 0.500409
# モデル
lightgbmとcatboostのridgeスタッキング
'cites'をStratifiedKFoldで10分割
この時点ではcolab proが来ていなかったので、colabのメモリが足りなくてbert系の特徴量を満足に作れませんでした。
終盤 チームマージ後
トピック特徴量
チームメイトからトピックモデルを用いた特徴量が効いたとのことで特徴量を分けてもらったところスコアが上がりました。
ProNEを用いた著者間ネットワークのEmbedding
おそらく他にはない特徴量です。ProNEという高速なグラフ埋め込み表現を生成するライブラリを用いて、データセット中の著者間のネットワークの情報(主著者・共著者の関係)を特徴量として取り入れました。理想は引用先/元みたいな情報があればベストでしたが、今回はないのでその代わりに作成しました。
github.com
この特徴量を入れて、Public LBで0.5を切りました。
cv:0.49345993682230704 pub:0.499121
特徴量の作り直し
この時点での僕はcitesが欠損値のデータに見切りをつけて、完全に捨てた状態で特徴量作りをしていました。
チームメイトのアドバイスで、テキストデータは特にスパースになりがちなのもあるので、全データから学習しているという話をいただいたので、なるほどと思い、colab proが来たあたりで一度学習データの作り直しをしました。(ただ、あんまり変化はなかった気はしている)
余談ですが、この辺りで僕のPCのモニタが壊れて作業効率がガタ落ちしました。(幸い外部ディスプレイは映ったのでなんとかなった)
BERT系特徴量
最終的にbert、scibert、robertaのEmbeddingsをabstract、title、comments、authorsに対してそれぞれ作成しました。
モデル
今まではLightGBMとCatboostのRidgeスタッキングのモデルを作成していました。
cvの分割方法はcitesをStratifiedKFoldです。
ここから少しモデルを複雑にします。
自分はできた特徴量は全部そのままモデルに入れてしまうことが割と多いですが(borutaとか使って特徴量削減とかすることもありますが...)、特徴量を入れすぎて他の特徴量が有効に作用しなくなっている可能性があるんじゃないかというアドバイスをいただいたので、特徴量を分けてモデルを作って汎用性向上も兼ねてモデルを少し複雑にしました。
モデルは下記の通りです。説明の便宜上、基本特徴量という言葉を使います。詳細については後ほど紹介します。
(全特徴量)+(基本特徴量+bert)+(基本特徴量+scibert) +(基本特徴量+roberta)の4つの種類のデータで学習させたlgbm+catboost+xgboost -> lgbm+catboost+ridge -> ridge スタッキング
ちなみにstage1のlightgbmだけcvを取っていたので参考までに
- 基本特徴量のみ(比較用にbert系なしでテスト)
cv: 0.5106523671584451
- 全特徴量
cv: 0.5092866170389334
- 基本特徴量+bert
cv: 0.5092094717909987
- 基本特徴量+scibert
cv: 0.5087591365076782
- 基本特徴量+roberta
cv: 0.5101846359593727
scibertは結構効いているなというのがわかると思います。
各段階でのcvは以下の通りです。
fold5
LV1 cv: 0.509084307754675
LV2 cv: 0.4941427303300941
LV3 cv: 0.49327801462008225
fold10
LV1 cv: 0.5056798694563699
LV2 cv: 0.49022210323680343
LV3 cv: 0.4892717381644779 <- これが個人でのベストのモデルです。Public:0.496693、Private:0.497997
特徴量
最終的に使用した特徴量について紹介を行います。この段階での特徴量作成はcitesが欠損のデータも用いた全データを使っています。
基本特徴量
stage1のどのモデルにも入れた特徴量です。
著者情報
doi
category
version
- 論文が投稿された時刻
- 論文が最後に更新された時刻
- 最後の更新と投稿された時刻の差分
- 論文が何回更新されたか
- 論文が更新されたかどうか
update_date
doi_cites
- doi_citesの値が0~4以下のものにそれぞれフラグ立て
- doi_cites - mean(doi_cites)
- mean(doi_cites) - doi_cites
- doi_cites / mean(doi_cites)
agg
agg_funcs = ['min','max','mean','median','sum','std','var','count']
target = 'doi_cites'
for c in ['first_author', 'first_author_WP', 'doi_prefix','license','doi_publisher']:
_df = train_test.groupby(c)[target].agg(agg_funcs).add_prefix(f'{target}_grpby_{c}_')
train_test = pd.merge(train_test, _df, on=c, how='left')
各種エンコーディング
ProNEのNode Embedding
テキスト系
前処理をかけて'authors', 'title', 'comments', 'abstract'に対してそれぞれ作成
def cleansing_hero_only_text(input_df, text_col):
## get only text (remove html tags, punctuation & digits)
custom_pipeline = [
hero.preprocessing.fillna,
hero.preprocessing.remove_html_tags,
hero.preprocessing.lowercase,
hero.preprocessing.remove_digits,
hero.preprocessing.remove_punctuation,
hero.preprocessing.remove_diacritics,
hero.preprocessing.remove_stopwords,
hero.preprocessing.remove_whitespace,
hero.preprocessing.stem,
]
texts = hero.clean(input_df[text_col], custom_pipeline)
return texts
def basic_text_features_transformer(input_df, column, cleansing_hero=None, name=''):
input_df[column] = input_df[column].astype(str).fillna('missing')
if cleansing_hero is not None:
input_df[column] = cleansing_hero(input_df, column)
_df = pd.DataFrame()
_df[name + column + '_num_chars'] = input_df[column].apply(len)
_df[name + column + '_num_exclamation_marks'] = input_df[column].apply(lambda x: x.count('!'))
_df[name + column + '_num_question_marks'] = input_df[column].apply(lambda x: x.count('?'))
_df[name + column + '_num_punctuation'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '.,;:'))
_df[name + column + '_num_symbols'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '*&$%'))
_df[name + column + '_num_words'] = input_df[column].apply(lambda x: len(x.split()))
_df[name + column + '_num_unique_words'] = input_df[column].apply(lambda x: len(set(w for w in x.split())))
_df[name + column + '_words_vs_unique'] = _df[name + column + '_num_unique_words'] / _df[name + column + '_num_words']
_df[name + column + '_words_vs_chars'] = _df[name + column + '_num_words'] / _df[name + column + '_num_chars']
return _df
- CountVectorizer()、TfidfVectorizer()でベクトル化した後、TruncatedSVDで次元削減
- word2vecで埋め込み
- 連なりを文章として見立ててword2Vecで埋め込み
'submitter', 'authors', 'abstract', 'doi_publisher'それぞれ適当にくっつけて、適当に次元数を決めて埋め込み
BERT系
それぞれTruncatedSVDで32次元に次元削減
おわりに
結果としてcv: 0.4892717381644779、Public: 0.496693、Private: 0.497997 のモデルが個人で作成したベストのモデルでした。
あとはうまいことチームメイトにアンサンブルしてもらってPublic: 0.485915、Private: 0.488907のサブミットを錬成してもらいました。感謝感激です。
チームマージが割と遅かったため、ある程度の特徴量共有とアンサンブルくらいしか行えなかったので、今度はもっと早い段階からチームを組んでじっくり取り組んでいくのもやってみたいなと思いました。
ただ、あまり共有しすぎてもモデルの多様性が生まれない気はするので、いい感じのバランス感覚を保つのはなかなか難しそうな気がしました。
また、差分学習は別として、特徴量的な面で何が重要だったのかいまいちよくわからなかったので、ここは少し気になる点です。(僕自身のモデルは最後までいまひとつ伸びなかったので)
ちなみにdoi_citesから派生した特徴量を突っ込み過ぎて、他の特徴量が有効に作用しなくなっているのではないか?というアドバイスをいただいて外して学習を回したりもしていましたが、差は出なかったので入れたままにしていました。
考慮し切れなかった点
今回のデータセットには、同じタイトルでsubmitterが別のデータ(表記揺れも含む)がtrainとtestに渡っていくつか存在していました。
これのdoi_citesがそれぞれ違っていたことから、doi_citesの作成過程を考えることが重要なのではという考えを持っていましたが、最後までここら辺を考慮に入れることができませんでした。
例:
# pickleで読み込み
train = pd.read_pickle('./features/train_data.pkl')
test = pd.read_pickle('./features/test_data.pkl')
train_test = pd.concat([train, test], ignore_index=True)
print(train_test['title'].value_counts())
print('-------------------------------------------------')
title = 'Discussion of: A statistical analysis of multiple temperature proxies:\n Are reconstructions of surface temperatures over the last 1000 years\n reliable?'
print(train_test[train_test['title']==title])
print(len(train[train['title']==title]), len(test[test['title']==title]))
出力
Discussion of: A statistical analysis of multiple temperature proxies:\n Are reconstructions of surface temperatures over the last 1000 years\n reliable? 12
Discussion of "Least angle regression" by Efron et al 8
Discussion of: Brownian distance covariance 7
Neutrino Physics 7
Discussion: Latent variable graphical model selection via convex\n optimization 6
..
Chiral 2$\pi$-exchange NN-potentials: Relativistic $1/M^2$-Corrections 1
Glassy dynamics in strongly anharmonic chains of oscillators 1
General Broken Lines as advanced track fitting method 1
What Types of COVID-19 Conspiracies are Populated by Twitter Bots? 1
Detectors for the Gamma-Ray Resonant Absorption (GRA) Method of\n Explosives Detection in Cargo: A Comparative Study 1
Name: title, Length: 909621, dtype: int64
-------------------------------------------------
id submitter ... doi_cites cites
144048 1104.4185 Lasse Holmstr\"{o}m ... 2 NaN
241257 1105.0519 Doug Nychka ... 1 NaN
243245 1105.2145 Gavin A. Schmidt ... 4 NaN
279850 1105.0524 Stephen McIntyre ... 1 NaN
373927 1104.4193 Peter Craigmile ... 1 NaN
463908 1105.0522 Jonathan Rougier ... 2 NaN
568236 1104.4178 Murali Haran ... 1 NaN
636339 1104.4171 L. Mark Berliner ... 1 NaN
798129 1104.4176 Richard A. Davis ... 1 NaN
863466 1104.4174 Alexey Kaplan ... 3 NaN
871483 1104.4188 Jason E. Smerdon ... 4 NaN
904070 1104.4195 Eugene R. Wahl ... 2 NaN
[12 rows x 16 columns]
9 3
ProNEが効いた理由
個人的な勘ですが、今回のデータセットではたくさん著者がいるデータがありました。ここら辺の情報を組み込むことができたのかなという気がします。ProNEを思いついたのが結構終盤だったのであまりEDAできてなく、データセット間で著者ネットワークが密につながっていたのかは確認できていません。
一応こんな論文は読んでいました。
www.jstage.jst.go.jp
最後
例の如くGithubリポジトリ貼ろうと思っていたのですが、今回結構コードをごちゃごちゃ書いていつも以上に見にくかったので、ブログに貼るのはやめようと思います。いつかひっそりとパブリックにするかもしれませんが。