Excelの表からSQLを作成してsqliteにぶち込む
タイトルの通りの内容です。
Excelのデータ(.xlsx)をDBにまとめて突っ込みたい時があると思います。 そんな時のためのスクリプトを書いたのでメモです。30分くらいで書いたので雑ですが。 (なおテーブルは初めからあるものとする)
サンプルデータは仙台のオープンデータを使用しました。(Excelで開いてすらいない)
データの例:
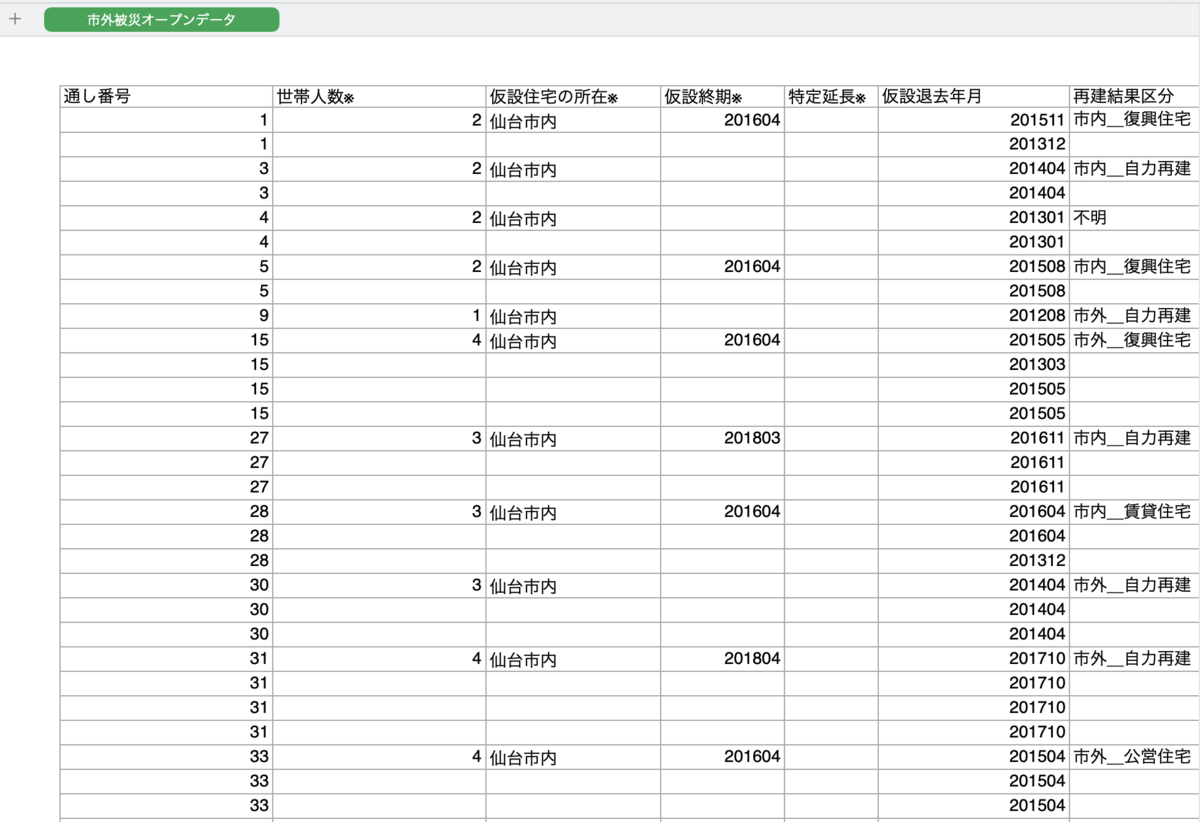
コード:
import sqlite3
import openpyxl
from pathlib import Path
db_path = Path('./data.db') # データを投げ込むdb
file_path = Path('./opendata_sigaihisai.xlsx') # 読み込み対象のファイル名
sheet_name = '市外被災オープンデータ' # 読み込み対象シート名
# エクセルファイル、シートの読み込み
wb = openpyxl.load_workbook(file_path)
ws = wb[sheet_name]
# 範囲データ取得
tbl = ws['A2':'Q10356']
# db接続
con = sqlite3.connect(db_path)
c = con.cursor()
# 範囲データを順次処理
for i, row in enumerate(tbl):
sql = 'INSERT OR REPLACE INTO static_data VALUES ('
for j, cell in enumerate(row):
# data_type: 文字列は’s’、booleanは'b'、日時型は'd', 数値とNoneは'n'
if cell.data_type=='s':
sql+=f'"{cell.value}", '
elif cell.data_type=='n':
sql+=f'{cell.value}, '
elif cell.data_type=='d':
pass
else:
print('OH NO') # エラー
exit()
# レコード登録
sql = sql[:-2]+')' # 末尾のスペースとカンマを削除して閉じる
sql = sql.replace('None', '""')
print(sql)
c.execute(sql)
con.commit()
# for s in c.execute('SELECT * from static_data'):
# print(s)
con.close()
水槽のアイドル オトシンクルスたん
皆さん魚は好きだろうか?
私は今年から熱帯魚を飼い始めたがそんな私を魅了してやまない魚がいる。そう、水槽のアイドルオトシンクルスだ。
つぶらな瞳とガラス面をもぐもぐする愛らしい動きで人々を魅了する彼らは苔を食べてくれる魚として、
熱帯魚を買う人なら誰しも一度は名前を聞いたことがある有名な魚だ。
性格は温和で、肉食魚以外のどんな魚とも一緒に過ごせるタンクメイトとしてその名を轟かせている。
さて、そんなオトシンクルスだが実はたくさん種類がある。(並オトシンは複数種類の総称であることは有名)
日本で有名なのはいわゆる並オトシンとオトシンネグロだろうか。私の水槽には並オトシンとニューゼブラオトシンが住んでいる。
並オトシンはキュートだが、ニューゼブラは非常に高貴な佇まいを見せてくれる。
www.shopping-charm.jp
そんなオトシンたちだが、私には一目見てみたい種類がある。それはグリーンオトシンだ。

http://www.rva.jp/zukan/pleco/green_otocin.htmlより
どうだろう、この宝石の如き輝き、非常に美しいではないか。
2014年のアルゼンチン便廃止以来入荷がないらしいが、またみられる日が来るのを楽しみにしている。
====================
おまけ
弊水槽のきゅーとなオトシン先輩

立てておいた方が食べやすいね pic.twitter.com/QZ6VDx2v46
— pop-ketle(KEN) (@ken7272popqjim) August 26, 2022
データサイエンティスト検定を受けた感想
この検定は2021年9月ごろに第1回が行われた最近できた資格だ。新しい資格なため比較的感想記事も少ない。これ受けた感想と振り返ってみての勉強のコツを書いてみる。
===================
この記事は受けてみて後から振り返ってみるあの知識が効いたなという感想話になります。
というのも私は無勉で受験しています。正確にいうとDS検定のための勉強はしなかったという感じです。
なぜなら第2か第3回目くらいの時に受けたので参考にできるものが特に無かったからです。(一応公式の問題集は出ていた気がするけど...)
勉強の参考になりそうなコンテンツ
+ データサイエンティスト スキルチェックリスト
DS検定を運営しているデータサイエンティスト協会が出しているチェックリストです。
www.datascientist.or.jp
受験した感想では結構これを元に必要な知識を考えている感じがありました。これを一回見ておくと雰囲気が掴める気がします。
足りないなと思う点は補強しといて良いかも??
+ 統計検定
資格を取るために他の資格の勉強をする。そんな馬鹿なと思うかも知れませんがおすすめです。特に統計の勉強には統計検定の参考書がおすすめです。レベル感でいうと3級から準2級くらいの感覚だと思います。
試験範囲に推定・検定、因果推論などの統計まわりの範囲が含まれているのですが、この辺りはノー知識だと解けないと思います。逆にいうとビジネス周りは「まぁ常識的にこうでしょ」みたいなノリで解ける問題がある気も。
データサイエンティスト検定™の試験範囲
データサイエンス力★1
統計数理基礎、線形代数基礎、微分・積分基礎、集合論基礎、統計情報への正しい理解、データ確認、俯瞰・メタ思考、データ理解、洞察、回帰・分類、評価、推定・検定、グルーピング、性質・関係性の把握、因果推論、サンプリング、データクレンジング、データ加工、特徴量エンジニアリング、方向性定義、軸だし、データ加工、表現・実装技法、意味抽出、時系列分析、機械学習、深層学習、自然言語処理、画像認識、映像認識、音声認識、パターン発見
感想
結構幅広い範囲の問題が出たなという印象です。DS協会が出している3つの柱「ビジネス力」「データサイエンス力」「データエンジニア力」に乗っ取って技術的な部分だけでなく、ビジネス的な部分も見られます。
というかデータサイエンティスト スキルチェックリストが問題範囲の感覚としてはかなり参考になる気がします。
DS検定、広く知識を概観するには悪くない資格なのかなと思いました。
そろそろリテラシーレベル以上も出てくるのかね?
...なんか思ってた以上に書くことなかったな?
CommonLit Readability Prizeから学ぶSentence BERTによるnoisy labelの吸収
はじめに
この記事はKaggle Advent Calendar 2021の15日目の記事です。 qiita.com
もともと書こうと思っていたことと少し方向転換して書いてるのでかなりきついです(なんでこんなことに...)。
コンテント
対象読者
「本記事は初心者に向けて」をイメージとして書いています。最近はKaggleでは単純なテーブルデータのコンペはあまり出ないので、タイタニックの次を探すのも難しいでしょう。 そういった方に向けて、次は自然言語処理コンペはいかがでしょうか?(なお、残念ながら自然言語処理コンペも単純なタスクのものはもうあまりない印象ですが... タスクの性質からノイジーラベルコンペになりがちな印象)
最近あった自然言語処理コンペの入賞者も書くことないと嘆いていました(私は参加していないのでどんなものだったのか概要しか知らないのですが)。
Chaiiのwinner's callマジで書くこと少ない。「他のインドの言語コーパス使いました。Pretrained model一杯試しました。何が何で効いたのかはよくわかりません。」で終わってしまう。CommonLitといいNLPコンペは何か捻りがないとこんな感じになってしまうのでは。
— Takami Sato (@tkm2261) 2021年11月29日
上記ツイートからも読み取れるように、単純なタスクではコンペとしては差を出しづらく、コンペとしてはもうなくなりつつあるのかも知れません(本当はここら辺の、機械学習アルゴリズムの成熟とデータ分析コンペの複雑化を絡めて、今後MLエンジニアを目指すに当たって求められていきそうなスキル、みたいなことをお題目にして記事を書きたかったが文章の神が降りてこなかった)。
少し話がそれました。次へ行きましょう。
(丁度この方とチームを組んでた方が、ソリューションを公開したようです。タイムリー!)
Kaggleのchaiiコンペで2位入賞した記事が、会社のエンジニアブログから公開されました〜
— kambehmw (@kambehmw) 2021年12月14日
マルチリンガルNLPや質問応答タスクにご興味ある方は読んでいただけますとありがたいです!
Kaggle「chaii - Hindi and Tamil Question Answering」コンペで2位入賞したお話 & 解法解説https://t.co/MzrQyzCO2l
自然言語とは
いや、そんなこと知ってるよという方が多いでしょうが、初心者向けなのでここからいきましょう。
自然言語とは、人間が自然に話すようになった言語です。
この説明では少しわかりにくいので、反対に人工言語について考えてみましょう。 人工言語は、人間が新しくルールを考えて設計した言語のことです。
一番わかりやすい例はプログラミング言語です。このほかに、エスペラント語や手話、ファンタジーで使われる架空言語も人工言語に入るようです。 人工言語 - Wikipedia
人工言語以外は全て自然言語、そう考えてみてはいかがでしょうか?
自然言語処理とは
自然言語処理(Natural Language Processing: NLP)とは読んで字の如く、自然言語を処理する技術一般のことをいいます。
自然言語処理を用いて解かれる一般的な大きな目標として下記のものがあります。
- 分類
- 翻訳
- 要約
- 対話
こうした大きな目標を達成するために、つまり文章の内容を機械に理解させるために、さまざまな技術が発展して来ました。
自然言語処理とデータ分析コンペ
さて、Kaggleのアドカレなので前座はほどほどにして、さっさとデータ分析コンペの話に入りましょう。
自然言語処理は人間が意思疎通の手段として広く使っている手法なだけに、応用範囲もかなり広いです。 上にあげたような分かりやすい「文章になんらかの処理」を行う以外に、意外なものに自然言語処理の手法を適用することでモデルの精度を向上させることが出来ます。
いくつか例として挙げると、商品の購入データは商品IDと紐付けて記号化されますが、この商品IDの列を文章として見なすことで、自然言語処理を用いて、購買行動を特徴量とすることが出来ます。ほかにも、ある単語の特徴が周囲の単語によって決まるという分布仮説(「走れ」の次は「メロス」が出て来やすいなど)と同様に、動画にIDを紐付けて、ある動画を見たユーザが次に見た動画群と結びつけることで動画の分散表現を得て、推薦アルゴリズムに用いる、などといったことも行われています。
といった感じで、ここまで記事を書いて、みんなアドカレどんなこと書いているのかなー?と見ていたらこんな記事を発見してしまったのだが...
私、こういう感じのものを書こうと思ってたのよね...もう記事書くの諦めて良いですか???
普段のブログ記事ならある程度内容被っても良いけど...アドカレでそれはなぁ......
さて、どうしようかな。
CommonLit振り返り
ということで急遽、中身を少し変更します。 今年はCommonLit Readability Prizeという自然言語処理のコンペがありました。これの振り返りということでいきましょう。 www.kaggle.com
このコンペのタスクは、文章のReadability(読みやすさ)を推定するというタスクでした。 特徴として、このReadabilityが小データかつnoisy(というとちょっと語弊がある気がするけど)というものがありました。
本コンペではReadabilityを「Bradley-Terry analysis」というものでスコアリングしているという大きな特徴がありました。 CommonLit Readability Prize: Target scores
Bradley-Terryアルゴリズムとは、今回のタスクにおいては、大雑把にいうと文章同士をどっちが読みやすいかで戦わせてレーティングをつける、いわゆるゲームでいうEloレーティングシステムのようなものでした。
3rd place solutionCommonLit Readability Prize: 3rd place solution (0.447 private - 3 models simple average)においても、以下のように語られています。
トレーニングデータ+公開・非公開データで5k弱のみのサンプル、そして、各サンプルは平均で46.47回、他のサンプルと比較されます。つまり、各テキストはデータセット全体の平均1%程度としか比較されていないことになります。チェスプレイヤーのEloを想像してみてください。そのプレイヤーは、全チェスプレイヤー人口の1%としか対戦しておらず、対戦相手は無作為に選ばれています。ノイズのほとんどは、比較回数の少なさによるものだと思います。
その上、どっちが読みやすいかを比較するのは人力。これじゃあ、そりゃnoisyになるわなというタスクでした。
さて、この問題を解決するにはどうすれば良いでしょうか?考えてみましょう。
Sentence Transformers
みなさん考えましたか?
私はコンペ中思いつきませんでした。データの分布の仕方が重要だろと思いKL Divの最小化に力を入れていたのですが全く成果を出せなくて泣きました。これに時間かけすぎたせいで、他の手法も試せず...うまくいかない手法に対しての損切りの感度みたいなものも身につけたいものです。
コンペ後にいくつかソリューションを読みましたが、自分が知っていた手法で、かつ使用したこともあるのに思いつかなかったということで、自戒を込めて今回は「Sentence Transformers」について紹介を行います。
Sentence Transformer、もう少しいうとSentence BERTですね。 これはBERTにPooling層をかまして、コサイン類似度などによって文章の類似度を計算することでより文章の類似度に着目したEmbeddings表現を得ることが出来ます。
経験則から言っても、先ほど紹介したHidehisa Araiさんの記事で紹介されている下記コードで得られるBERTのEmbeddings表現よりも文章の類似度を考慮したEmbeddings表現を得られることが多いです。 テーブルデータ向けの自然言語特徴抽出術
import torch
import transformers
from transformers import BertTokenizer
class BertSequenceVectorizer:
def __init__(self, model_name="bert-base-uncased", max_len=128):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model_name = model_name
self.tokenizer = BertTokenizer.from_pretrained(self.model_name)
self.bert_model = transformers.BertModel.from_pretrained(self.model_name)
self.bert_model = self.bert_model.to(self.device)
self.max_len = max_len
def vectorize(self, sentence: str) -> np.array:
inp = self.tokenizer.encode(sentence)
len_inp = len(inp)
if len_inp >= self.max_len:
inputs = inp[:self.max_len]
masks = [1] * self.max_len
else:
inputs = inp + [0] * (self.max_len - len_inp)
masks = [1] * len_inp + [0] * (self.max_len - len_inp)
inputs_tensor = torch.tensor([inputs], dtype=torch.long).to(self.device)
masks_tensor = torch.tensor([masks], dtype=torch.long).to(self.device)
bert_out = self.bert_model(inputs_tensor, masks_tensor)
seq_out, pooled_out = bert_out['last_hidden_state'], bert_out['pooler_output']
if torch.cuda.is_available():
return seq_out[0][0].cpu().detach().numpy() # 0番目は [CLS] token, 768 dim の文章特徴量
else:
return seq_out[0][0].detach().numpy()
ここでいくつか参考となりそうなサイトを紹介しておきましょう。
- 分散密ベクトル探索エンジンValdとSentence-BERTを使った類似文書検索を試す - エムスリーテックブログ
- はじめての自然言語処理 第9回 Sentence BERT による類似文章検索の検証
- 【日本語モデル付き】2020年に自然言語処理をする人にお勧めしたい文ベクトルモデル - Qiita
(個人的に近傍探索が好きなので、この中だとエムスリーテックブログの話が好きです)
えーっと、でなんでしたっけ...?
そうそう、CommonLitでしたね。1位の解法がこちらなのですが1st place solution - external data, teacher/student and sentence transformers
この解法の1番の差別化ポイントが、sentence bertを用いて、外部データから学習用データセットの各サンプルに対して、最も類似しているデータを5件ずつ引っ張ってきて追加データとして用いた、というところです。
他の回答は割と、モデルめっちゃ作ってアンサンブルしたよみたいなのばかりなのですが、1位を取れるかどうかの差はここにあったのじゃないかなと考えています。
外部データが使えないコンペも多いのですが、その場合でも、例えば今回でいえば、似た文章を集めてきてその平均値をその文章のReadabilityとする、などでlabelのnoisyさを吸収できるのではないかなと思っています。(実験できてないので本当か?みたいなところありますがすみません)
というわけで、noisy labelに対する対応策としてのSentence BERT、皆さんも試してみてはいかがでしょうか?
Hugoの自作テーマを作ろう! vol.1
Hugo テーマ作成
とりあえず、ベーシックなテンプレをインストールしましょう。
git clone https://github.com/gohugoio/hugoBasicExample.git
次に、自作のテーマを作りましょう。 クローンしたリポジトリに移って、早速テーマを作成します。
cd hugoBasicExample hugo new theme [Your theme name]
とのことなので私は
hugo new theme GoldExperience
でいきます。themes/以下にフォルダが作成されているのを確認できると思います。
まず、hugoBasicExample/config.tomlを弄ってテーマの読み込み設定を行います。下記を書き込みましょう(激うまギャグ)。
theme = "GoldExperience"
Semantic UI インストール
いつの日かVuetify使いたいと言っていました。 Hugoの自作テーマを作ろう![外伝] - pop-web
それは今も変わらないのですが、Hugoとは相性が悪そうです。
Semantic UIというのが気に入ったので、今回はこれを使ってみましょう。
『Simpler Setup』からダウンロードしてきてstatic配下に設置
こんな感じのフォルダ構成になっていると思います(package.jsonはないかも)。
. ├── LICENSE ├── archetypes │ └── default.md ├── layouts │ ├── 404.html │ ├── _default │ ├── index.html │ └── partials │ ├── footer.html │ ├── head.html │ └── header.html ├── package.json ├── static │ ├── Semantic-UI-CSS-master │ ├── css │ └── js └── theme.toml
まず、ちゃっちゃとSemantic UIを読み込みつつ画像を表示するようにします。
相変わらずコードブロックで表示がおかしくなるので、行間を詰めて書いてます(多分コードブロックでファイル名を表示するためのCSS周りがおかしいんだろうけど、ファイル名表示できないのはかなり不便なのでそのまま放置してます)。皆さんは適宜改行を入れてください。私も実コードは改行入れてます。
{{ define "main" }}
<h1>Hello World</h1>
{{ end }}
<head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> {{ hugo.Generator }} <title>{{ .Title }} {{ default "::" .Site.Params.titleSeparator }} {{ .Site.Title }}</title> <link rel="stylesheet" href="https://fonts.googleapis.com/css?family=Roboto:100,300,400,500,700,900"> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@mdi/font@latest/css/materialdesignicons.min.css"> <link rel="stylesheet" type="text/css" href="{{"/Semantic-UI-CSS-master/semantic.min.css" | relURL}}"> </head>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.1.1/jquery.min.js"></script> <script src="{{"/Semantic-UI-CSS-master/semantic.min.js" | relURL}}"></script> <script src="{{"/js/main.js" | relURL}}"></script>
{{ define "main" }}
<article>
{{ .Content }}
</article>
{{ end }}
<!DOCTYPE html> <html lang="{{ .Page.Language | default "ja" }}" class="js csstransforms3d"> {{- partial "head.html" . -}} <body> {{- partial "header.html" . -}} <div id="content"> {{- block "main" . }}{{- end }} </div> {{- partial "footer.html" . -}} </body> </html>
大雑把に説明するとbaseof.htmlが全ての基本です。
baseof.html内の下記の部分でコンテンツ(とりあえず最初はindex.html)を読み込んでいます。
<div id="content"> {{- block "main" . }}{{- end }} </div>
あとは、見ればなんとなくわかると思いますが、適宜head.html、header.html、footer.htmlを読み込んでいます。
hugoBasicExample/themes/GoldExperience/static/js/main.jsは自分でファイルを作成しましょう。今は空です、後々書き込みます。
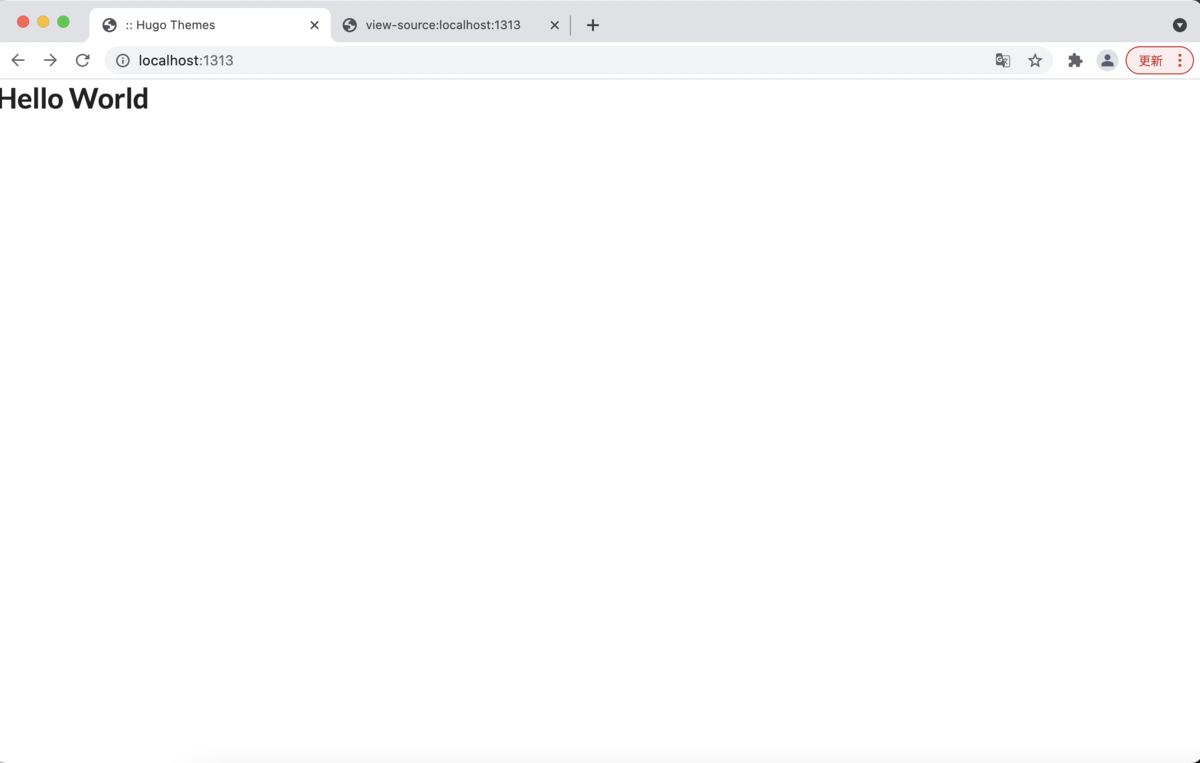
ここらで、Hugoのサーバを立ち上げてみましょう。
$ hugo server // config.tomlにthemeを設定していない場合はこっち $ hugo server -t GoldExperience
多分こんな感じになると思う。これからheader.htmlを書き込んでいく。
まずメニューバーみたいなものが欲しいので作ってみようと思う。
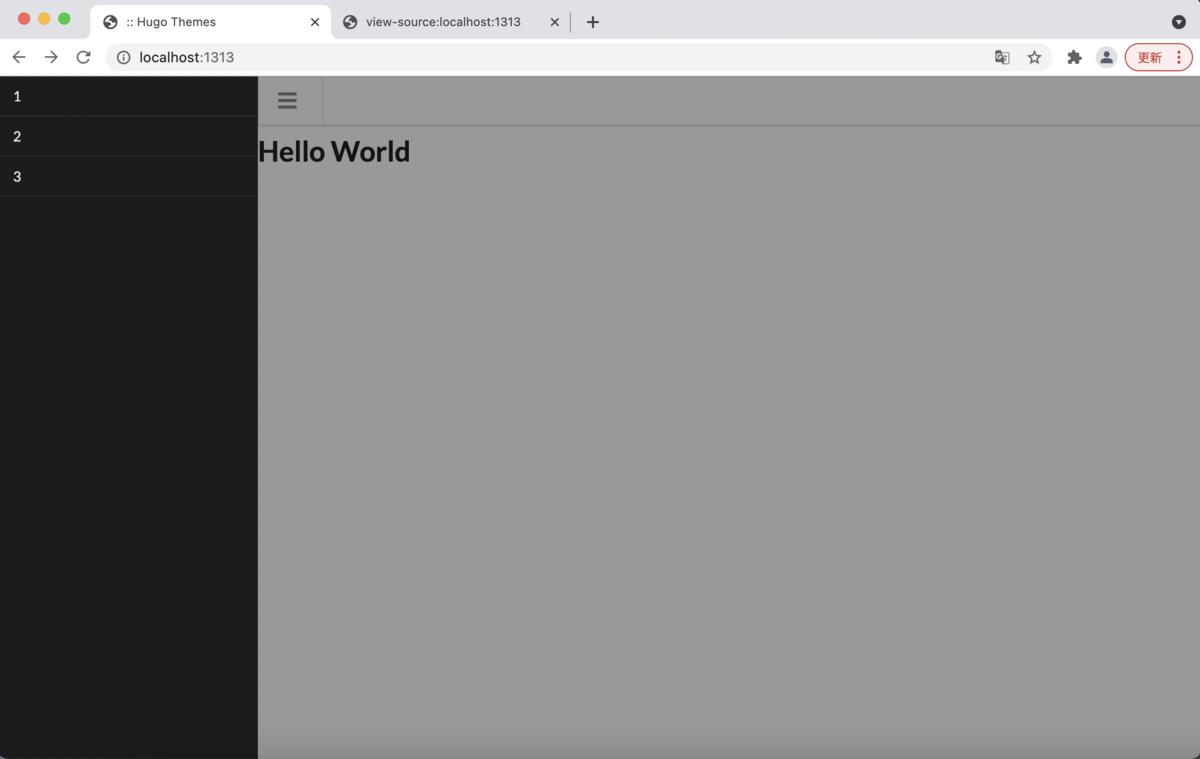
前述したように、今回はSemantic UIというライブラリを使う。 header.htmlと.jsファイルに書き込んでいく。
<div class="ui celled grid"> <div class="row"> <div class="three wide column"> <!-- サイドバー トグルボタン --> <div class="ui fixed menu"> <div class="menu"> <div id="js-sidebar" class="item"><i class="icon large grey content"></i></div> </div> </div> <!-- サイドバー --> <div class="ui sidebar inverted vertical menu"> <a class="item">1</a> <a class="item">2</a> <a class="item">3</a> </div> </div> <div class="thirteen wide column"> <p></p> </div> </div> </div>
$('#js-sidebar').click(function() {
$('.ui.sidebar').sidebar('toggle');
});
左上の三つのバーみたいなものをクリックするとトグル式でメニューのような物がスライドして出てくるようになったと思う。 かっこいいな!
ゴリゴリ触ってサイドバーを弄っていく。
static配下にimagesフォルダを作って、top_icon.jpgを配置して読み込んで、これをサイドバーの上部に配置してみる(猫画像にしておいた)。ついでにconfig.tomlにauthorの情報を追加して配置する。
かわいいので Flag | Semantic UI このサイトを参考に、ロケーションに応じて国の旗が立つようにする。
<div class="ui celled grid"> <div class="row"> <div class="three wide column"> <!-- サイドバー トグルボタン --> <div class="ui fixed menu"> <div class="menu"> <div id="js-sidebar" class="item"><i class="icon large grey content"></i></div> </div> </div> <!-- サイドバー --> <div class="ui sidebar inverted vertical menu"> <div class="ui segment"> <img class="ui centered medium image" src="/images/top_icon.jpg"> <p style="text-align: center"> {{ if .Site.Author.name }} Name: {{ .Site.Author.name }} <br>{{ end }} {{ if .Site.Author.location }} Place: {{ .Site.Author.location }}<i class="{{ .Site.Author.location | urlize }} flag"></i>{{ end }} </p> </div> <a class="item" href={{ .Site.BaseURL }}>TOP PAGE</a> {{ range .Site.RegularPages }} <a class="item" href={{ .Permalink }}>{{ .Name }}</a> {{ end }} </div> </div> <!-- <div class="thirteen wide column"> <p>{{ .Site.Title }}</p> </div> --> </div> </div>
デフォルトで色々書いてあるので、端折って書くがこんな感じで[author]の情報を書く必要がある。(流石に読みにくいので、今回は改行をそのままにする。改行タグが余分に含まれるけどまぁ仕方ない。)
baseURL = "https://gohugo.io" title = "Theme GoldExperience" paginate = 3 languageCode = "ja" DefaultContentLanguage = "ja" enableInlineShortcodes = true ignoreErrors = ["error-remote-getjson"] theme = "GoldExperience"[outputs] home = ["html", "rss", "json"]
[author] name = "pop-ketle" location = "Japan"
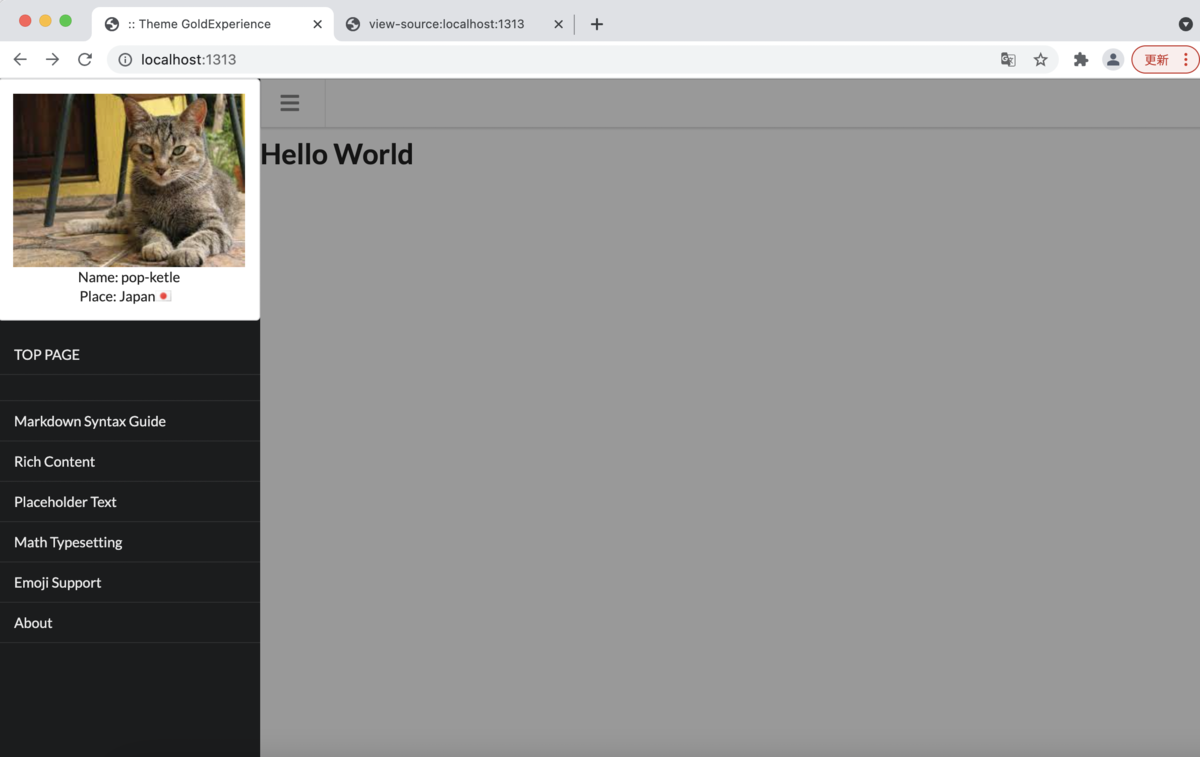
それっぽくなったかな?
archives/が文字として出ないから何も文字の入っていないサイドバーが入っているけど、少し様子見。 Hugoのテンプレートエンジンをまだあまり理解していないので、ページ周りは実際にサイトを作ってから調整したい。
Hugoの自作テーマを作ろう![外伝]
概要
本記事は、マークダウンの静的htmlジェネレーターであるHugoとVuetifyというVueのフロントエンドを合体させてテーマを作れないか試行錯誤した失敗エピソードをまとめたものです。
無かったことにしてしまおうかとも思いましたが、とりあえずこれはこれで勉強になるので、一旦ここでまとめて出すことにします。
導入
とりあえず最初はここら辺を参考にします。
gohugo.io github.com www.neujournal.net
環境構築
brew install hugo
とりあえず、ベーシックなテンプレをインストールしましょう。
git clone https://github.com/gohugoio/hugoBasicExample.git
これがあると自作のテーマが動くかテストできるようです。
Create
自作のテーマを作りましょう。 クローンしたリポジトリに移って、早速テーマを作成します。
cd hugoBasicExample hugo new theme [Your theme name]
とのことなので私は
hugo new theme UltraPop
でいきます。themes/以下にフォルダが作成されているのを確認できると思います。
こんな感じのフォルダ構成。
.
├── LICENSE
├── README.md
├── config.toml
├── configTaxo.toml
├── content
│ ├── _index.md
│ ├── about.md
│ ├── archives.md
│ ├── homepage
│ │ ├── about.md
│ │ ├── index.md
│ │ └── work.md
│ └── post
│ ├── _index.md
│ ├── emoji-support.md
│ ├── markdown-syntax.md
│ ├── math-typesetting.md
│ ├── placeholder-text.md
│ └── rich-content.md
├── layouts
├── resources
│ └── _gen
│ ├── assets
│ └── images
├── static
└── themes
└── UltraPop
├── LICENSE
├── archetypes
│ └── default.md
├── layouts
│ ├── 404.html
│ ├── _default
│ │ ├── baseof.html
│ │ ├── list.html
│ │ └── single.html
│ ├── index.html
│ └── partials
│ ├── footer.html
│ ├── head.html
│ └── header.html
├── static
│ ├── css
│ └── js
└── theme.toml
theme.tomlを弄りましょう。
GitHub - gohugoio/hugoThemes: A curated directory of Hugo themes
こいつを参考に弄ります。
# theme.toml template for a Hugo theme # See https://github.com/gohugoio/hugoThemes#themetoml for an example name = "UltraPop" license = "MIT" licenselink = "https://github.com/pop-ketle/Hugo-Theme/blob/main/themes/UltraPop/LICENSE" description = "pop-ketle's theme for portfolio" homepage = "http://example.com/" tags = ["Blog", 'Portfolio', 'Docs', 'Gallery'] features = [] min_version = "0.41.0" [author] name = "pop-ketle" homepage = "" # If porting an existing theme [original] name = "" homepage = "" repo = ""
とりあえずこんなもんかな。
nameはデフォで入ってると思うので、licenselinkとdescriptionとauthor書けばとりあえず十分だと思う。知らんけど。
多分公開する時にタグで検索しやすくなると思うので、Complete List | Hugo Themesの右端にあるタグからそれっぽいのを適当に選んだ。featureは良くわからん。homepageはまだないのでとりあえずノータッチで。
ここらで、とりあえず動かしてみよう。
$ hugo server # こっちじゃないとダメかも $ hugo server -t UltraPop
ローカルサーバが立ったと思います。私はhttp://localhost:1313/でした。クリックして見ましょう。人類が月面に降り立つ最初の一歩です。
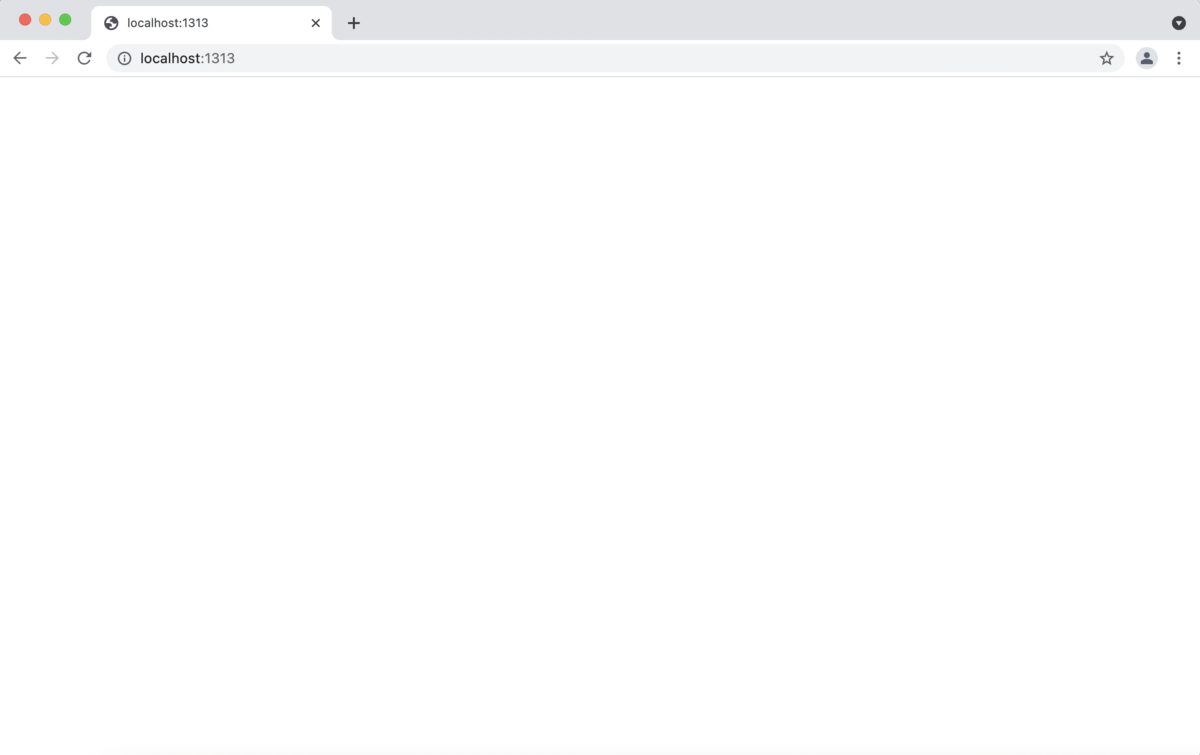
......見事に真っ白ですね.........
まぁ、当然何も書いていないのでそれはそうなります。コンテンツを作っていきましょう。
とりあえずindex.htmlにハローワールドの儀式をしましょうか。 ということで
hello world
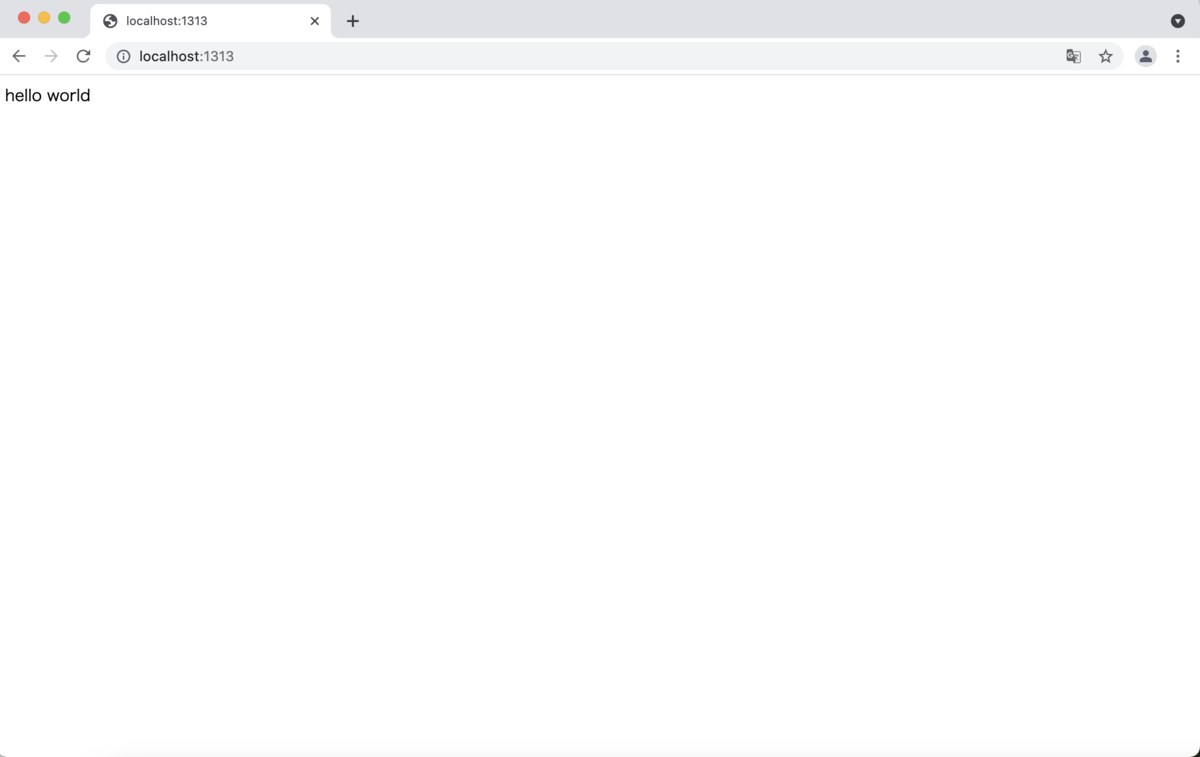
...やったぜ!(ここまでテンプレ)
ちなみにHugoはファイルを保存するたびに、rerun(という呼び方で良いのか知らないけど)するので、変更が自動で反映されるので便利です。
...さーてここからどうするかな......
実を言うとGo langにもフロントエンドにも別に詳しいわけじゃないのでここからどうしたら良いか、全く謎である。
Vuetify
Vuetify使ってみたいんだよなぁ...そう思っていたので張り切ってVuetifyを試して見ることにする。人生は冒険や!
 なんだこいつ...トップページですら格好良すぎる...ということで「はじめよう」してみる。
なんだこいつ...トップページですら格好良すぎる...ということで「はじめよう」してみる。
まず.js系のパッケージを管理するのにnode.js入れる必要があるぽい。
Macなので...
brew install nodebrew mkdir -p ~/.nodebrew/src nodebrew install-binary latest nodebrew use v17.1.0
とりあえず新しいのを入れてアクティブにした。JavaScriptなんかめんどくさいなやっぱり。
zsh使ってるので.zshrcに書き込んでパスを通す。ターミナル再起動してnodeコマンドが使えるようになったことも確認。
export PATH=$HOME/.nodebrew/current/bin:$PATH
$ node -v v17.1.0 $ npm -v 8.1.2
とりあえずよし!
外伝のさらに外伝
これはVuetifyインストール失敗ルートです。
初見ではここでいきなりパッケージを入れ始めたのだが、まず
$ cd themes/UltraPop $ npm init
する必要があるらしいということでやり直した。 package.jsonが作成される。
次はVueを入れて、ついにVuetifyを入れる!はずなのだがNuxt経由とWebpack経由の二つがあるらしい。 違いが全く分からない。Vuetifyを使いたいだけなのに、NuxtかWebpackを入れる必要があって、これを入れるためにVueを、vueを入れるために、node.jsを、node.jsを入れるためにnodebrewを入れてとしないといけない。JavaScriptは本当にごちゃごちゃしていて嫌いだ。
まぁ、pip installとかも裏でよしなに依存関係うまいことやってくれてるんだろうけど。
とりあえず、Nuxtは聞いたことあるし、見た感じWebpackも包含しているみたいなのでNuxtを入れてみる。
$ npm install vue $ npm install @nuxtjs/vuetify -D $ npm list ultrapop@1.0.0 /Users/home/Desktop/work/Python/mywork/hugoBasicExample/themes/UltraPop ├── @nuxtjs/vuetify@1.12.1 └── vue@2.6.14
私のディレクトリ構成のおかげでPythonとか書いてあるけど気にしない。多分これでいいんだろう。
Vuetifyの公式サイトには
インストールしたら、nuxt.config.jsファイルを更新して、ビルドにVuetifyモジュールを含めます。
と書いてあるがnuxt.config.jsは見当たらない。
...いやこれnuxtいるか?
ということでまたやり直す。
本ルート
nuxt.config.jsが見つからなかったので、vue CLI経由で行うことにする。 多分static/js/ 配下に自分でファイル作って入れとけばうまくいきそうだけど、良く分からんしな。
$ npm init $ npm install vue # vue CLIを入れる $ npm install -g @vue/cli $ vue create vue_app $ cd vue_app $ vue add vuetify $ npm list ultrapop@1.0.0 /Users/home/Desktop/work/Python/mywork/hugoBasicExample/themes/UltraPop ├── @nuxtjs/vuetify@1.12.1 └── vue@2.6.14
あれ?nuxtくん勝手にはいってるんだけど...(めんどくさいので見なかったことにする。)
多分これでいいんだろう。途中途中、選択肢がいくつか出てきたけどそれっぽいのを選んでおいた。 もう少ししたらVuetify v3が出るみたいだし、そしたらここら辺の記述は陳腐化するだろうからいらないと思うので省く。
ついでに、作法らしいので.gitignoreにnode_modules/を追加しておく。
つーか、たかだかパッケージのインストールだけなのにやり方多すぎだろ。これだからJavaScriptってやつは...(以下略)
ちょっとだけHugoのテーマ開発
Vuetifyのインストールも終わったので、またサーバを立ち上げる。
$ hugo server -t UltraPop
さーてここからどうすればいいんだろうな?(フロントエンド ヌーブ並感)
とりあえずheaderを作るか。
このサイトや、他の人の既存テーマを参考に適当に書いてみる。 it-omurice.tokyo
悲しいことに、はてなでコードを書くと改行が変なことになるので、キチキチに詰めて書いているが、実際はもうちょっとちゃんと改行を挟んでゆとりを持たせて書いている、ということは断っておく。
<!DOCTYPE html>
<html lang="{{ .Page.Language | default "ja" }}" class="js csstransforms3d">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
{{ hugo.Generator }}
<title>{{ .Title }} {{ default "::" .Site.Params.titleSeparator }} {{ .Site.Title }}</title>
</head>
{{ define "main" }}
<h1>Hello World</h1>
{{ end }}
とりあえずタブに出てくるサイト名が変わったのがわかるだろうか?これはconfig.tomlを参照している。
テーマはできれば公開したいので、今はあまり弄らないでおいた。
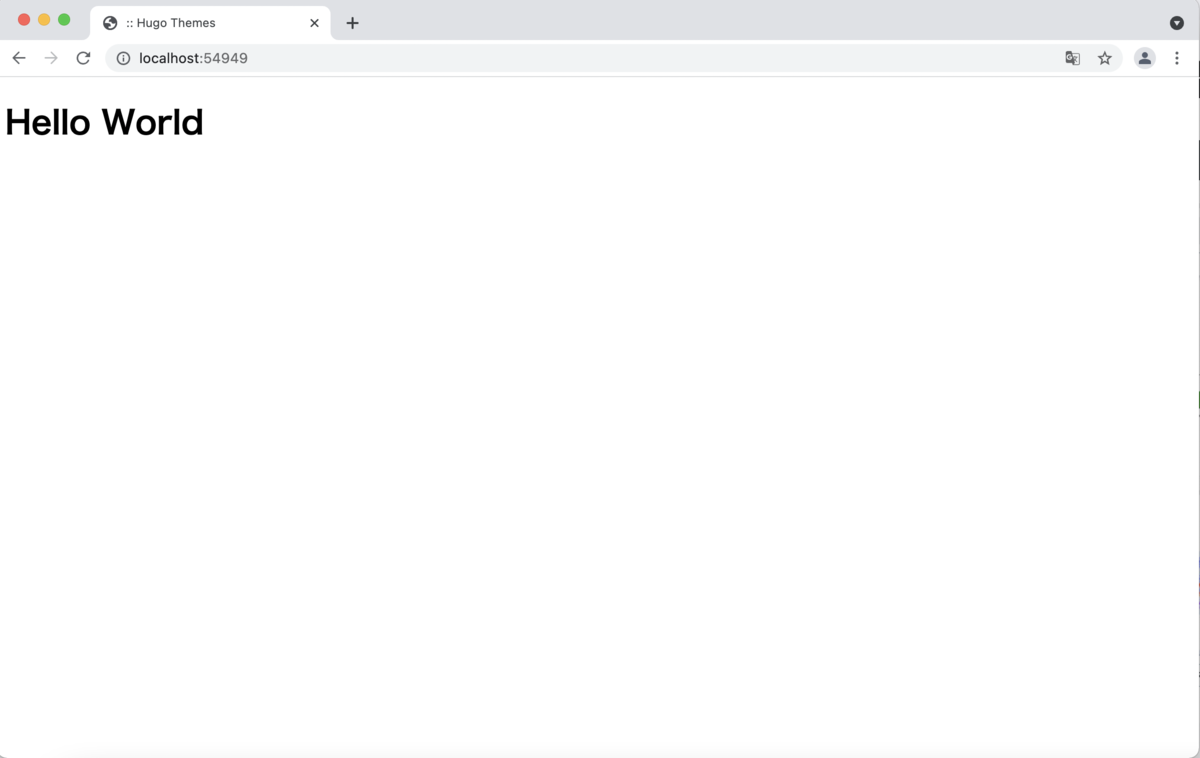
ちょこちょこコードに変更を入れていく。 これは、普段のページがどう書かれるかを書いたものだ。 {{ .Content }}が記事の中身になる(はず)。
{{ define "main" }}
<article>
{{ .Content }}
</article>
{{ end }}
ところで色々調べてたんだけど、HugoとVuetifyを組み合わせた記事が見当たらないので、Vuetifyを使う計画は止まっている。 なんか相性が悪いというか、HugoかVuetifyどっちか片方で済むんじゃないかという気がしてきている。組み合わせるメリットってあるのか?(この辺りから怪しい空気が漂ってますね...)
ともかく今は最初の目的の一つだった、seleniumを使ったデータ分析コンペの結果の自動スクショで戦績更新ページを作りたい。やろう。
下記コマンドでcontent/ 配下にページが作成される。Hugoはこうやって作成した.mdをhtmlファイルに変換してくれる。
$ hugo new [PAGENAME/~.md]
今回はデータコンペの戦績ページを作成したいので、こんな感じの名前にした。
$ hugo new deta_competitions/index.md
ここから似たファイル名が増えるのでわかりにくくなってしまうが、こんな感じの変更を加えた。これでトップページに作成したページへのリンクが並ぶはずである。 例によってコードブロックの改行タグがおかしなことになっているのでキチキチだが許して欲しい。
{{ define "main" }}
<h1>Hello World</h1>
<h1>記事一覧</h1>
{{ range first 10 .Pages }}
<a href={{ .Permalink }}>{{ .Name }}</a>
{{ end }}
{{ end }}
本当はこの記事を書いた目的は、Kaggleなどの戦績を定期的にSeleniumで自動スクショしておいてくれるポートフォリオを作りたいというものだったのだが、2021年11月16日現在、Kaggleの規約をよく読んでみるとスクレイピングしたらどうなるか、わかってるよね?と書いてあったので泣く泣く断念した。アカウントを消されたら元も子もない。

ということで、とりあえずヘッダーに幾つかのサイトへの画像リンクを作成した。画像アイコンは割とやっつけなので、出来が良くないのでおいおい綺麗にしていこうと考えている。また、画像ファイルはthemes/UltraPop/static/images/の下に置いておくと以下のようなリンクの書き方で、うまいことHugoがやってくれる。(*あとでhugoコマンドでサイトを生成してみたら画像リンクがうまく貼れていなかったのでこれは嘘です。)
<a href="https://www.kaggle.com/popketle"><img src="/images/kaggle_logo_icon.png" alt="", width="30" height="30"></a> <a href="https://signate.jp/users/37802"><img src="/images/signate_logo_icon.png" alt="", width="30" height="30"></a> <a href="https://comp.probspace.com/users/pop-ketle/0"><img src="/images/probspace_logo_icon.png" alt="", width="30" height="30"></a> <a href="https://atcoder.jp/users/popketle"><img src="/images/atcoder_logo_icon.png" alt="", width="30" height="30"></a> <a href="https://github.com/pop-ketle"><img src="/images/github_logo_icon.png" alt="", width="30" height="30"></a> <a href="https://qiita.com/pop-ketle"><img src="/images/qiita_logo_icon.png" alt="", width="30" height="30"></a>
Vuetifyでの開発
そろそろVuetifyでの開発に移りたい。それに伴ってvue系のファイルの置き場所を変えた。 themes/UltraPop/static/配下に作り直した。
また、npm run serve errorがエラーが出るので、次の記事を参考に
node.js - Error message "error:0308010C:digital envelope routines::unsupported" - Stack Overflow
export NODE_OPTIONS=--openssl-legacy-providerをコマンドに打ち込んで解決した。Macはどうもopenssl周りの挙動が怪しくていけない。
これによってvuetify画面が出るようになった。しかし、これをどうすればHugoとくっ付ければ良いのか?まぁ、とりあえずできそうなことを試しにやっていくしかない。人生そういうもの。
長い時間が経ってしまった......

次の記事を参考に進めていったが、うーん、悲しいかな、どうしてもHugoとvueのテンプレートエンジンが競合したり、パス周りがうまくいかなくて厳しいことがわかり始めた。Vueだけならどうにかなりそうなんだけど、Vuetifyを使ってcomponentを作る形で開発していくと同してもパスが通らない。
ということで、この方針は諦めてHugoで.jsonファイルを吐き出してそれを読み込んでVuetifyで画面構築しようかなと思う...んだけど、そうするとHugoっているのかな...というわけで色々悩み中。
次回、本編に続く...かな?
色々考えると、既存のHugoのテーマで困ってないし、Notionとか使ってもいいしで、モチベーションの持って行きようがなくて困っちゃうよね。
ProbSpace 論文の被引用数予測コンペ参加記 Public: 5位 Privete: 4位(pop-ketle版)
結論
チームマージはいいぞ
はじめに
ハローワールド、pop-ketleです。
期間空いてしまいましたが、ProbSpace 論文の被引用数予測コンペ参加記です。
参加ユーザー数: 168人中、Public: 5位 Privete: 4位でした。
概要
「コンペティション概要」「背景課題・目的」「本コンペティションの特徴」を コンペサイトから引用します。
コンペティション概要 本コンペでは、論文投稿サイト(プレ・プリントサーバー)の公開情報を用いて、 被引用数の予測モデル開発にチャレンジいただきます。 背景課題・目的 「論文の被引用数」とは、その研究論文が他の論文で引用された回数を示す数値であり、 被引用数が多いほど重要性の高い研究とみなされやすいことから、 査読論文の本数、掲載ジャーナル・カンファレンスの影響力 等と並び、 研究功績を評価する一指標として用いられています。 そこで本コンペにおいてはタイトル・アブストラクトへの言葉選び、ジャーナル・カンファレンスの選択がどれだけ引用数に影響するか考察したいと思います。 研究者・学生の皆さまにとって、論文執筆や研究テーマを選ぶ上でのインサイトとなれば幸いです。 本コンペティションの特徴 今回のコンペでは、学習データの一部に目的変数(被引用数)が含まれておらず、 代わりにDigital Object Identifier(DOI)により計算された低精度被引用数が代替変数として付与されています。 現実世界の問題においては必ずしも充分な量の教師データを用意できるとは限らず、 そのような場合においては弱教師あり学習が1つの有効な手段となります。 本コンペを通して弱教師ありにおけるモデル開発に親しんでいただければ幸いです。
コンペ概要について所感
個人的にかなり面白いタスクだなと感じていて、結構初期の方から参加してました。思うほど参加者が増えなかったのが不思議です。
また、今回のコンペでは弱教師あり学習に親しんで欲しいということで、DOIから算出された低精度被引用数(doi_cites)という、いわば弱目的変数みたいなものがあるのが特徴的でした。
ただ、いくつかソリューションを拝見させていただきましたが、結局あんまり弱教師あり学習ならではのソリューションみたいなものはなかった気がしています。
自身の取り組み
最初に断っておくと、僕自身のモデルはPublic:0.496693、Private:0.497997と本来なら4位という栄光に浴することのできるスコアではありませんでした。
チームメイトの人には感謝しかありません。アンサンブルでスコアが結構上がった印象があるので、その点で多少なりともチームのモデルの多様性に寄与できていたら嬉しいなという感じです。
ただ、特徴量部分では、他の人と比べてそこまで差が出る足りない特徴量があったか?という感想は持っていて、何がスコアに差が出ていたのか正直今でもよくわからないなという印象は持っています。 (差分学習はやっていなかったので、これが大きな違いになっていたというのはあり得る。)
大きな差が出る特徴量はなくて、小さなところが積もり積もっての結果なのかな?と今は考えています。(最後の方で一度特徴量を始めから作り直したのですが、見返すとそこでいくつか作成し忘れた特徴量があったので。)
序盤・中盤
弱教師あり学習が特徴らしい?コンペということで、「よし!弱教師ありぽいことするぞ!!」と 目的変数のcitesがないデータに対して、まずcitesを予測するモデルを作成し、trainデータのcitesの欠損値を埋めることで、使用可能なデータを増やす(いわゆるpseudo labeling的な)ことを取り組みとしてここしばらく試していました。
ただ、これはcv:0.245859、pub:0.501828 とあんまりうまくいきませんでした。(doi_citesを説明変数に入れてるので過学習してる)
ここら辺の取り組みは下記ディスカッションでも少し話しています。
論文の被引用数予測 | ProbSpace
この時の段階では、この「citesとかなり高い相関を持っているdoi_citesがどうやって作成されたものなのか」について考えをめぐらせていましたが、結局よくわからないまま終わってしまいました。
終盤 チームマージ前
Publicで0.5が切れなくてうだうだしていたので、誰かチームマージして0.5を切るワザップを教えてくださいと泣きつきました。大体コンペ終了の1週間前ですかね。
論文コンペ誰かチームマージしません?当方0.5切れません
— KEN(pop-ketle) (@ken7272popqjim) 2021年3月21日
(マージ期限とかないよね?)
結果として優秀なチームメイトに恵まれ、3人でチームを結成することができました。
メモが残っていたので、 この時点での僕のソロでのベストスコアのモデルをさっくり紹介しておきます。
cv: 0.4946567032659036 pub: 0.500409 # モデル lightgbmとcatboostのridgeスタッキング 'cites'をStratifiedKFoldで10分割
この時点ではcolab proが来ていなかったので、colabのメモリが足りなくてbert系の特徴量を満足に作れませんでした。
終盤 チームマージ後
トピック特徴量
チームメイトからトピックモデルを用いた特徴量が効いたとのことで特徴量を分けてもらったところスコアが上がりました。
トピックモデルを用いた特徴量なし
cv:0.4970250184226564 pub:0.503534トピックモデルを用いた特徴量あり
cv:0.4956426088968561 pub:0.502278
ProNEを用いた著者間ネットワークのEmbedding
おそらく他にはない特徴量です。ProNEという高速なグラフ埋め込み表現を生成するライブラリを用いて、データセット中の著者間のネットワークの情報(主著者・共著者の関係)を特徴量として取り入れました。理想は引用先/元みたいな情報があればベストでしたが、今回はないのでその代わりに作成しました。
この特徴量を入れて、Public LBで0.5を切りました。
cv:0.49345993682230704 pub:0.499121
特徴量の作り直し
この時点での僕はcitesが欠損値のデータに見切りをつけて、完全に捨てた状態で特徴量作りをしていました。
チームメイトのアドバイスで、テキストデータは特にスパースになりがちなのもあるので、全データから学習しているという話をいただいたので、なるほどと思い、colab proが来たあたりで一度学習データの作り直しをしました。(ただ、あんまり変化はなかった気はしている)
余談ですが、この辺りで僕のPCのモニタが壊れて作業効率がガタ落ちしました。(幸い外部ディスプレイは映ったのでなんとかなった)
BERT系特徴量
最終的にbert、scibert、robertaのEmbeddingsをabstract、title、comments、authorsに対してそれぞれ作成しました。
モデル
今まではLightGBMとCatboostのRidgeスタッキングのモデルを作成していました。
cvの分割方法はcitesをStratifiedKFoldです。
ここから少しモデルを複雑にします。
自分はできた特徴量は全部そのままモデルに入れてしまうことが割と多いですが(borutaとか使って特徴量削減とかすることもありますが...)、特徴量を入れすぎて他の特徴量が有効に作用しなくなっている可能性があるんじゃないかというアドバイスをいただいたので、特徴量を分けてモデルを作って汎用性向上も兼ねてモデルを少し複雑にしました。
モデルは下記の通りです。説明の便宜上、基本特徴量という言葉を使います。詳細については後ほど紹介します。
(全特徴量)+(基本特徴量+bert)+(基本特徴量+scibert) +(基本特徴量+roberta)の4つの種類のデータで学習させたlgbm+catboost+xgboost -> lgbm+catboost+ridge -> ridge スタッキング
ちなみにstage1のlightgbmだけcvを取っていたので参考までに
- 基本特徴量のみ(比較用にbert系なしでテスト)
cv: 0.5106523671584451 - 全特徴量
cv: 0.5092866170389334 - 基本特徴量+bert
cv: 0.5092094717909987 - 基本特徴量+scibert
cv: 0.5087591365076782 - 基本特徴量+roberta
cv: 0.5101846359593727
scibertは結構効いているなというのがわかると思います。
各段階でのcvは以下の通りです。
fold5
LV1 cv: 0.509084307754675
LV2 cv: 0.4941427303300941
LV3 cv: 0.49327801462008225fold10
LV1 cv: 0.5056798694563699
LV2 cv: 0.49022210323680343
LV3 cv: 0.4892717381644779 <- これが個人でのベストのモデルです。Public:0.496693、Private:0.497997
特徴量
最終的に使用した特徴量について紹介を行います。この段階での特徴量作成はcitesが欠損のデータも用いた全データを使っています。
基本特徴量
stage1のどのモデルにも入れた特徴量です。
著者情報
- 第一著者
- 第一著者の所属
- 総著者数
doi
- doiのprefix("/"でスプリットした前部分)
- 外部データ 論文の被引用数予測 | ProbSpace からpublisher、journals、dois
category
- カテゴリー数
- カテゴリーを分解してフラグ立て
version
- 論文が投稿された時刻
- 論文が最後に更新された時刻
- 最後の更新と投稿された時刻の差分
- 論文が何回更新されたか
- 論文が更新されたかどうか
update_date
- year
- month
- day
- dayofweek
doi_cites
- doi_citesの値が0~4以下のものにそれぞれフラグ立て
- doi_cites - mean(doi_cites)
- mean(doi_cites) - doi_cites
- doi_cites / mean(doi_cites)
agg
agg_funcs = ['min','max','mean','median','sum','std','var','count']
target = 'doi_cites'
for c in ['first_author', 'first_author_WP', 'doi_prefix','license','doi_publisher']:
_df = train_test.groupby(c)[target].agg(agg_funcs).add_prefix(f'{target}_grpby_{c}_')
train_test = pd.merge(train_test, _df, on=c, how='left')
各種エンコーディング
ProNEのNode Embedding
- sparse
- spectral
テキスト系
前処理をかけて'authors', 'title', 'comments', 'abstract'に対してそれぞれ作成
- 前処理
def cleansing_hero_only_text(input_df, text_col):
## get only text (remove html tags, punctuation & digits)
custom_pipeline = [
hero.preprocessing.fillna,
hero.preprocessing.remove_html_tags,
hero.preprocessing.lowercase,
hero.preprocessing.remove_digits,
hero.preprocessing.remove_punctuation,
hero.preprocessing.remove_diacritics,
hero.preprocessing.remove_stopwords,
hero.preprocessing.remove_whitespace,
hero.preprocessing.stem,
]
texts = hero.clean(input_df[text_col], custom_pipeline)
return texts
- テキストの基本特徴量
def basic_text_features_transformer(input_df, column, cleansing_hero=None, name=''):
input_df[column] = input_df[column].astype(str).fillna('missing')
if cleansing_hero is not None:
input_df[column] = cleansing_hero(input_df, column)
_df = pd.DataFrame()
_df[name + column + '_num_chars'] = input_df[column].apply(len)
_df[name + column + '_num_exclamation_marks'] = input_df[column].apply(lambda x: x.count('!'))
_df[name + column + '_num_question_marks'] = input_df[column].apply(lambda x: x.count('?'))
_df[name + column + '_num_punctuation'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '.,;:'))
_df[name + column + '_num_symbols'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '*&$%'))
_df[name + column + '_num_words'] = input_df[column].apply(lambda x: len(x.split()))
_df[name + column + '_num_unique_words'] = input_df[column].apply(lambda x: len(set(w for w in x.split())))
_df[name + column + '_words_vs_unique'] = _df[name + column + '_num_unique_words'] / _df[name + column + '_num_words']
_df[name + column + '_words_vs_chars'] = _df[name + column + '_num_words'] / _df[name + column + '_num_chars']
return _df
- CountVectorizer()、TfidfVectorizer()でベクトル化した後、TruncatedSVDで次元削減
- word2vecで埋め込み
- 連なりを文章として見立ててword2Vecで埋め込み
'submitter', 'authors', 'abstract', 'doi_publisher'それぞれ適当にくっつけて、適当に次元数を決めて埋め込み
BERT系
それぞれTruncatedSVDで32次元に次元削減
- bert
- roberuta
- scibert
おわりに
結果としてcv: 0.4892717381644779、Public: 0.496693、Private: 0.497997 のモデルが個人で作成したベストのモデルでした。
あとはうまいことチームメイトにアンサンブルしてもらってPublic: 0.485915、Private: 0.488907のサブミットを錬成してもらいました。感謝感激です。
なんかよくわからんまま貢献せずにスコア上げてもらって、感謝しかない
— KEN(pop-ketle) (@ken7272popqjim) 2021年3月26日
感想戦
チームマージが割と遅かったため、ある程度の特徴量共有とアンサンブルくらいしか行えなかったので、今度はもっと早い段階からチームを組んでじっくり取り組んでいくのもやってみたいなと思いました。 ただ、あまり共有しすぎてもモデルの多様性が生まれない気はするので、いい感じのバランス感覚を保つのはなかなか難しそうな気がしました。
また、差分学習は別として、特徴量的な面で何が重要だったのかいまいちよくわからなかったので、ここは少し気になる点です。(僕自身のモデルは最後までいまひとつ伸びなかったので)
ちなみにdoi_citesから派生した特徴量を突っ込み過ぎて、他の特徴量が有効に作用しなくなっているのではないか?というアドバイスをいただいて外して学習を回したりもしていましたが、差は出なかったので入れたままにしていました。
考慮し切れなかった点
今回のデータセットには、同じタイトルでsubmitterが別のデータ(表記揺れも含む)がtrainとtestに渡っていくつか存在していました。 これのdoi_citesがそれぞれ違っていたことから、doi_citesの作成過程を考えることが重要なのではという考えを持っていましたが、最後までここら辺を考慮に入れることができませんでした。
例:
# pickleで読み込み
train = pd.read_pickle('./features/train_data.pkl')
test = pd.read_pickle('./features/test_data.pkl')
train_test = pd.concat([train, test], ignore_index=True)
print(train_test['title'].value_counts())
print('-------------------------------------------------')
title = 'Discussion of: A statistical analysis of multiple temperature proxies:\n Are reconstructions of surface temperatures over the last 1000 years\n reliable?'
print(train_test[train_test['title']==title])
print(len(train[train['title']==title]), len(test[test['title']==title]))
出力
Discussion of: A statistical analysis of multiple temperature proxies:\n Are reconstructions of surface temperatures over the last 1000 years\n reliable? 12
Discussion of "Least angle regression" by Efron et al 8
Discussion of: Brownian distance covariance 7
Neutrino Physics 7
Discussion: Latent variable graphical model selection via convex\n optimization 6
..
Chiral 2$\pi$-exchange NN-potentials: Relativistic $1/M^2$-Corrections 1
Glassy dynamics in strongly anharmonic chains of oscillators 1
General Broken Lines as advanced track fitting method 1
What Types of COVID-19 Conspiracies are Populated by Twitter Bots? 1
Detectors for the Gamma-Ray Resonant Absorption (GRA) Method of\n Explosives Detection in Cargo: A Comparative Study 1
Name: title, Length: 909621, dtype: int64
-------------------------------------------------
id submitter ... doi_cites cites
144048 1104.4185 Lasse Holmstr\"{o}m ... 2 NaN
241257 1105.0519 Doug Nychka ... 1 NaN
243245 1105.2145 Gavin A. Schmidt ... 4 NaN
279850 1105.0524 Stephen McIntyre ... 1 NaN
373927 1104.4193 Peter Craigmile ... 1 NaN
463908 1105.0522 Jonathan Rougier ... 2 NaN
568236 1104.4178 Murali Haran ... 1 NaN
636339 1104.4171 L. Mark Berliner ... 1 NaN
798129 1104.4176 Richard A. Davis ... 1 NaN
863466 1104.4174 Alexey Kaplan ... 3 NaN
871483 1104.4188 Jason E. Smerdon ... 4 NaN
904070 1104.4195 Eugene R. Wahl ... 2 NaN
[12 rows x 16 columns]
9 3
ProNEが効いた理由
個人的な勘ですが、今回のデータセットではたくさん著者がいるデータがありました。ここら辺の情報を組み込むことができたのかなという気がします。ProNEを思いついたのが結構終盤だったのであまりEDAできてなく、データセット間で著者ネットワークが密につながっていたのかは確認できていません。
一応こんな論文は読んでいました。
最後
例の如くGithubリポジトリ貼ろうと思っていたのですが、今回結構コードをごちゃごちゃ書いていつも以上に見にくかったので、ブログに貼るのはやめようと思います。いつかひっそりとパブリックにするかもしれませんが。