atmaCup#10参加記(pop-ketle版)
はじめに
ハローワールド、pop-ketleです。
どうやら、前回のatmaCup#8から1つもブログ記事書いてないんですね。 僕の頭の中では色々コンペ出てブログで参加記を書いたつもりだったのですが、どうやら妄想だったようです。近いうちにちゃんと書きたいですね。
今回はタイトルの通り、atmaCup#10の参加記です。できるだけ早いうちに書こうと思っていましたが、結局遅れて旬を逃した感じになっています。
概要
今回のatmaCupは「美術作品の属性情報から、ユーザーがどの作品を良いと思うか、を予測する問題」でした。評価指標はRMSLE。
僕の結果は、チーム 525中、Public/Private両方とも62位で全くshakeはなしでした。 CVとLBが割と綺麗に相関しているイメージだったので、スコア的にはshakeしないだろうけど、結構LBが密だったので順位の上下はあるだろうなと思っていたのですがshakeしませんでした。
atmaCup#9でもshakeしなかったので、shakeしない才能があるのかもしれません(student cup 2020の話はNG)
一応TOP15%には入れたのですが、正直個人的には今ひとつな順位で、かなり不完全燃焼感あります。 まぁ、学んだものはたくさんあったのでよし。
今回、本当にスコアが密で、サブして寝て起きると順位がガッツリ落とされているみたいな激しい戦いでした。 最初の想定では、結構ガッツリatmaCupのために時間取れる予定だったのですが、なんか引っ越しの準備とかがあって思っていた以上に時間がなくて厳しかったです。
初心者歓迎ということで思いっきり歓迎(LBでボコられる)をされました。
atmaCupの"初心者歓迎"は「ボコボコにしてやるから、初心者はかかってこいよ」の意味である(嘘です) #atmaCup
— KEN(pop-ketle) (@ken7272popqjim) 2021年3月12日
そういったわけで、隙間時間にディスカッションの実装をパクって魔改造するぐらいしかできず、自分なりの工夫とかができなかったところが、スコアに如実にあらわれているかなと言った感じです。
働きながら参加している人がたくさんいる以上、言い訳でしかないんですが。 働きながら参加してる人には頭が上がりませんね。
序盤
コンペ開催前に投稿されたTabNetについてのディスカッションにビビり散らかしました。何がやばいかって、コンペまだ始まってないんですよね。戦いはコンペが始まる前からもうすでに始まっているんだということを分からさせられました。
このディスカッションの投稿と共に戦いの火蓋が切られたと言っても過言ではありません。(そうか?)
(Linkのこっちの記事もかなり良さそう)TabNetとは一体何者なのか?
TabNet、僕はあんまり知らないのですが(というかいきなり名前だけ見るようになって、どこで出てきたあれなのか全く知らないのですが、なんかのコンペで強かったんですかね?)TabNetについて日本語でここまで、まとまっている記事はあまりないと思うので、この記事はもっと広く知られるべきだと思います。
今回のタスクについて
ところで、今回のタスクの「美術作品の属性情報から、ユーザーがどの作品を良いと思うか、を予測する問題」ってかなり面白いですよね。ともすれば、個々人の感性によって大きく評価が変わりそうな美術作品の評価を予測して、スコアをつけるという、人じゃないと理解できないような、言語化しにくいものを機械に予測させるというのは、かなり面白いなと僕は思っています。
美的感覚の一般化ってできるもんなんですかね?うーん、面白いですね。
僕は別に芸術・絵画の専門家ではないので、これから割と適当言いますが、美的感覚って点で存在しているものではなくて、ある種のコンテキストの中で存在するものなんですよね。
絵は描かれただけではダメで、絵に対して解釈や評価、つまり、見る人が必要なんです。 そうした絵に対しての解釈や評価が重ねられて、重ねられて、積もり積もったものが絵の重みになるんですね。
つまるところ、その絵が描かれた背景や、有名な絵だというのを知っているからこそ、すごい絵なんだと判断でき、面白さ・美的感覚を共有できるわけです。
それを機械に学習させるというのは、やはりかなりチャレンジングな問題だと思っています。
それっぽく聞こえましたか?だとしたら幸いです。(冗談めかして書きましたが、割と本気で思っています、とだけは付け加えておきます。)
中盤
このコンペのちょい前に、atmaCupの猛者のpaoさんが短期間コンペの戦い方というLT?プレゼンをしてくれました。そのため、今回のコンペでは費用対効果というものを少し意識していました。 speakerdeck.com
と言っても時間かかりそうなのは後回しにする、とかどれくらい効きそうかを意識するとかの普通の取り組みですが。
具体例を挙げるとBERT系は結構チューニングとか真剣にやりだすと無限に時間が溶けるのを知っていたので、今回はサクッと試しやすいTF-IDFやw2vでの処理を基本にテストを回して、BERTは後回しにするなどしていました。
ただまぁ、今回データセットが小さめだったので、結局BERTも言うほど時間かからなかったのですが...
BERTはあんまりパラメータいじらず適当に特徴量作って、あんまり効かないなーとかやっていたところ、他の人は結構効いていたらしいので、少し失敗点ですね。
やはり、なんだかんだ現状はNLPはBERT最強な気がします。
取り組み
色特徴量
個人的な感覚として、色の特徴量はなんとなく効かない気がしていたのであまり触りませんでした。
object_idごとにaggregationして、下記特徴量を加えました。
- ratioのmax、minを計算
- RGB, HSVごとに'min'、'max'、'mean'、'std'、'var'、'max-min'
- 代表色による特徴量を参考にratioが最大のRGB、HSV、平均のRGB、HSV
若干効きました。
パレットの可視化 こちらのディスカッションをみて、意外と色とライクに傾向が見えてるみたいで逆に驚いたのですが、実際色の特徴量はどこまで効いたのでしょうね?
copastaさんの [Public 3rd/Private 1st] solution では、色で行列を作って、固有値を作って計算するところまでやって、それなりに効いたようですが、ここまでやらないと効かなかった感じなんでしょうか?
作家の情報
maker、principal_maker、principal_maker_occupationの情報を紐づけて単純に加えました。
今思い返してみるとここはもうちょっと深掘りしたかったなぁというところ。
作品のタイプ
作品のタイプを 複数対応しているテーブルデータを結合してみる(material.csv) こちらを参考にしながらくっつけました。
object_type=paintings がかなりFeature Importance上で上位に来ていたので、絵画はライクが貰いやすいのかなーとか考えていました。
historical_person
作品にhistorical_personが写っているかどうかのフラグと、その人数の特徴量を加えました。
作れるから作ってみたと言う感じで効いた気はしないです。
technique
作品のtechniqueをクロス集計表に成型してマージしました。
CVが落ちたのでやめました。
production_place
production_placeと、 geopyを使ってproduction_placeを地名→国名に変換する を参考に国名に変換したものをクロス集計表に成型してマージしました。
特に効いた感じはしなかったかなと言う感じ。
materials
materialの取り扱い こちらを参考に、materials をある程度まとめて数を減らした上で結合しました。
後述するw2vの埋め込みの際も、まとめないものと、まとめたもの両方作ってみても良かったかもしれない。
w2vを使って、系列を文章として埋め込み
これは以前見かけてから、ずっと試してみたかった手法で、今回、Arai-sanのわかりやすいディスカッションのおかげで、あまり苦労せずに実装できたのですごく感謝しています。 Word2Vecを使ってmaterial, technique, object_collectionなどを特徴ベクトル化する
Feature Importance上もかなり効いており、私の主戦力でした。
material、technique、object_collectionだけでもかなり効いたので、自分はここを深掘りして、principal_makerやhistorical_personなど、目につくものを手当たり次第くっつけてw2vで埋め込みました。
年代
ドメイン知識(西洋絵画とオランダの画家) このディスカッションのドメイン知識の話が面白かったので、年代を時期と世紀で分けられるように適当にビニングしてみました。
結構期待していたのですが、あんまり効かなかったです。
収集に際して資金提供などを行った情報があるかどうか
収集に際して資金提供などを行った情報、acquisition_credit_lineがあるかどうかについてフラグを立てました。
期待より効いたイメージ。(とはいえ、特徴量の少ない初めのうちから加えてたために、Feature Importanceが高かったように見えてただけかもしれない。実際、特徴量が増えてきた後半はFeature Importanceの彼方に流されていった。)
著者について
- 著者がデータセット中に何回出てくるか
よく分からない、特に効いてはなさそう。
- 著者ごとに何種類の sub_title を持っているか
終了後に落ち着いてみると、なんでsub_titleの数にしたのかよく分からない。永遠の謎。
- 著者ごとにデータセットに存在する作品の年度の最小・最大・平均
結構効いた。
テキスト
テキストのカラム、['principal_maker','principal_or_first_maker','title','description','sub_title','long_title','more_title']に対して、処理を行った。
まず、一般的な特徴量。コードで書いた方がわかりやすい気がするので、コードで記述。
# text の基本的な情報をgetする関数
def basic_text_features_transformer(input_df, column, cleansing_hero=None, name=''):
input_df[column] = input_df[column].astype(str)
_df = pd.DataFrame()
_df[column + name + '_num_chars'] = input_df[column].apply(len)
_df[column + name + '_num_exclamation_marks'] = input_df[column].apply(lambda x: x.count('!'))
_df[column + name + '_num_question_marks'] = input_df[column].apply(lambda x: x.count('?'))
_df[column + name + '_num_punctuation'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '.,;:'))
_df[column + name + '_num_symbols'] = input_df[column].apply(lambda x: sum(x.count(w) for w in '*&$%'))
_df[column + name + '_num_words'] = input_df[column].apply(lambda x: len(x.split()))
_df[column + name + '_num_unique_words'] = input_df[column].apply(lambda x: len(set(w for w in x.split())))
_df[column + name + '_words_vs_unique'] = _df[column + name + '_num_unique_words'] / _df[column + name + '_num_words']
_df[column + name + '_words_vs_chars'] = _df[column + name + '_num_words'] / _df[column + name + '_num_chars']
return _df
(これよく見たら、cleansing_hero(textheroのテキスト処理パイプライン)使ってないですね。バグを発見してしまった...)
次に、CountVectorizerとTfidfVectorizerでベクトル化したものを、TruncatedSVDで64次元に落として、特徴量として加えた。
w2vで64次元に落としたものも加えた。
両者とも、結構効いた。
ちなみに下記のtextheroを使ったテキスト処理をしたら結構LBが上がった。今回はテキストの前処理が効果的だったようである。
# 英語とオランダ語を stopword として指定
custom_stopwords = nltk.corpus.stopwords.words('dutch') + nltk.corpus.stopwords.words('english')
def cleansing_hero_only_text(input_df, text_col):
## get only text (remove html tags, punctuation & digits)
custom_pipeline = [
hero.preprocessing.fillna,
hero.preprocessing.remove_html_tags,
hero.preprocessing.lowercase,
hero.preprocessing.remove_digits,
hero.preprocessing.remove_punctuation,
hero.preprocessing.remove_diacritics,
hero.preprocessing.remove_stopwords,
hero.preprocessing.remove_whitespace,
hero.preprocessing.stem,
lambda x: hero.preprocessing.remove_stopwords(x, stopwords=custom_stopwords)
]
texts = hero.clean(input_df[text_col], custom_pipeline)
return texts
BERT
['title', 'description', 'long_title']に対して、 後述の言語判定を行なった後に、言語別に英語、オランダ語、その他でそれぞれ対応するモデルを使って学習させて得たEmbeddingsを、TruncatedSVDを使って128次元に削減したものを特徴量として加えた。
自分の場合、今回の使い方ではBERTはあまり効かず、w2v、tfidfを使ったものの方がよく効いた。
ただ、ここはすごく反省点で、 2位のもーぐりさんのように最初に英語に変換してしまってから、BERT使った方がよかったなと反省した。(おそらく英語の方がコーパスの質、量がいいので)
また、言語別に対応するモデルを使おうと考えていたからなのか、['title', 'description', 'long_title']に対してしかBERTを使わなかったのがかなり間抜けすぎる。もっと使えるテキストがあるのに...
当時の自分をビンタしたい。
言語の判定
['title', 'description', 'long_title']に対して、 タイトルの言語判定特徴 このディスカッションを参考に言語判定を行った。
テキストの特徴量を加えたら、Feature Importanceの彼方に流されていったが、序盤はFeature Importanceの上位にいたので結構効いていたと思われる。
サイズ
sub_titleから作品のサイズを抽出して単位をmmに統一する このディスカッションを参考にサイズを抜き出しました。
gotoさんの講座2 [講座#2] EDA・モデルの改善 とかで、sub_titleの長さが特徴量の上位に来ていました。 これは基本的に作品の大きさを表すもので、この長さが長いと言うことはそれだけ作品が大きい、もしくは立体的、と言うことになります。
そこで、1.0で穴埋めをした上で、h*w、h*w*t、h*w*t*dをそれぞれ計算して、作品の大きさを表す特徴量を作成しました。これは結構効きました。
各種エンコーディング
適当にラベルエンコーディング、カウントエンコーディング、ターゲットエンコーディングをしました。
今回特にターゲットエンコーディングが結構効きました。
モデリング
最初はLightgbmでテストをして進めて、コンペ後半でLightgbmとCatboostの出力をRidgeスタッキングするいつものムーブをしました。 likesに対して、StratifiedKFold(n_splits=5)です。
そろそろ手札にMLP系のモデルを仕込みたいです。
あまりいい順位でもなかったので、パラメータチューニングより他のもっと本質的なとこだろということで、パラメータチューニングせず、LGBMRegressorに対してだけ下記のいつものパラメータを与えました。 ラーニングレートぐらいはいじってみてもよかったかな。
lgbm_params = {
'objective': 'rmse', # 目的関数. これの意味で最小となるようなパラメータを探します.
'learning_rate': 0.1, # 学習率. 小さいほどなめらかな決定境界が作られて性能向上に繋がる場合が多いです、がそれだけ木を作るため学習に時間がかかります
'reg_lambda': 1., # L2 Reguralization
'reg_alpha': .1, # こちらは L1
'max_depth': 6, # 木の深さ. 深い木を許容するほどより複雑な交互作用を考慮するようになります
'n_estimators': 10000, # 木の最大数. early_stopping という枠組みで木の数は制御されるようにしていますのでとても大きい値を指定しておきます.
'colsample_bytree': 0.5, # 木を作る際に考慮する特徴量の割合. 1以下を指定すると特徴をランダムに欠落させます。小さくすることで, まんべんなく特徴を使うという効果があります.
# bagging の頻度と割合
'subsample_freq': 3,
'subsample': .9,
'importance_type': 'gain', # 特徴重要度計算のロジック(後述)
'random_state': RANDOM_SEED,
}
選択した2つのモデルは下のような結果となりました。
CV: 1.00752、 Public: 0.9861、Private: 1.0042
CV: 1.00704、 Public: 0.9821、Private: 1.0038
選択した中でベストなモデルのFeature Importanceはこんな感じ(どっかバグらせて箱ひげ図になってないけど許して)
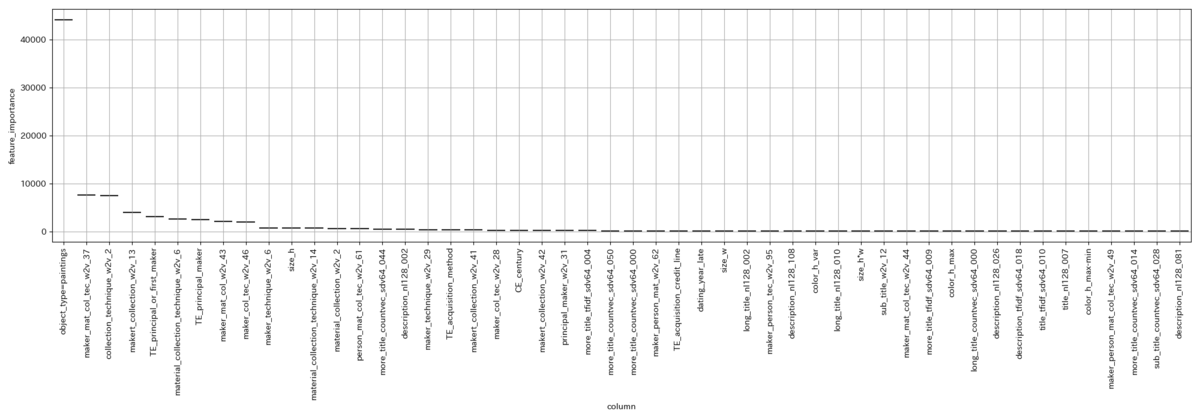
持ってたベストのサブミッションは、
CV: 0.99648、Public: 0.9892、Private: 1.0016
でした。
LBを見すぎて、Trust CVの基本を忘れたのは残念なところですかね。そこまで大きな差ではないですが。
Feature Importanceはこんな感じ。

おわりに
改めてまとめてみると、本当にディスカッションの後追いしかしてないですね...
ほんとは自分でディスカッション投稿もしたかったのですが、実装速度を出せなかったというのが正直なところです。 simpletransformersを使ったBERTによるEmbeddings抽出とか書こうと思えば書けたんだけどな...
Embeddingsをt-SNEとかで可視化みたいなのもやりたかったんだけど、ディスカッション書く時間的余裕と速度を出せませんでした。
コンペでは実装速度も大切ですね、特にディスカッションは。
ところで、今回上位陣でpseudo labelを使っている人がいた覚えがあるのですが、pseudo labelを試そうか考慮に入れるスコアの基準とかって、みなさん持っているのでしょうか? 自分の基準だと今回、pseudo labelを試そうとは全く思わなかったのですが、なんかポイントというか勘所というかあるんですかね?pseudo label、何度か他コンペでも試してるんですけど、なかなか効かないんですよね。気になります。
今回のコンペは色々データを見れて楽しかったです。学びもかなりあり(特にw2vの埋め込み)、思う存分歓迎していただきました、もう僕のライフは0です。
ただ、少し今後に対して不安も持ちました(今後はさらにコンペに割ける時間が減るであろうため)。社会人参加者の方マジ、リスペクトっす。
そういえば、反省点として今回のコンペでは、チームも組みたかったんですよね。
短期間コンペだと早めにチームを組んでおきたいところなのですが、勇気がなくて自分からチームマージを言い出せなかったり、思ったよりコンペに割ける時間がなくて相手に迷惑かもとか考えたりして、チーム組みたいと言い出せなかったのを強く反省しています。
ということで、正直今回のコンペはかなり不完全燃焼ですが、これが現状の自分の実力ということで真摯に受け止めます。これで今回のatmaCup参加記を終わろうと思います。
早く環境を落ち着けたいですね。コンペもできる限り出たいし、出るつもりですが、しばらく資格の勉強をそろそろ真剣に始めないといけないとかがあったりして、少し落ち着いて地力を貯める時期かもしれませんね。
なんか色々自分に足りないものが見えて、少し気疲れしてしまいますね。 正直、仕事も面白くなさそうだし、しばらく耐える時期になりそうです。はぁ...
最後に特に整備してませんが、Githubのリポジトリを公開します。例によってスターもらえたら私の励みになります。
ディスカッションでも実験管理のやり方について少し話が出ていましたが、私はあまりファイルを増やしたくないので、一つのファイルを書き足しながら進めてsubごとにcommitして、メッセージにメインで変更を加えたファイル名とCV、public LBのスコアを書く方式に現在はしています。参考にでもどうぞ。
ちなみに、もう少し期間が長いコンペの場合はNotionを併用して情報をまとめています。(実際はNotionあまり上手く使えてないけど)
github.com
atmaCup#8参加記(pop-ketle版)
はじめに
こんにちは。お久しぶりです。
2020年12月4日(金)〜12月13日(日)に開催されたatmaCup#8に参加しました。
僕はatmaCupに出るのは2回目でした。
初めての時は忘れもしない#6 Sansan × atmaCup。
詳しく話していいのか忘れちゃったので、今回はさっとしか触れませんが(思い出したら感想書くかも)あの時受けた屈辱だけは忘れられず、何度も夢に見ました。
そう...初めてみるタイプのデータに何をしたらいいか何もわからず、ほぼ2週間何もできずに、それこそディスカッションで公開されたベースラインに毛を生やすことすらできずに、この人たち一体何をディスカッションしてるんだ?と自分の無力をひたすら味わい続けて、リーダボードのほぼ底辺で泣いたあの屈辱を。
その屈辱を返す時が、ついにやってきたのです。
今回は初心者向けと銘打たれており、初心者から中級者へ、一つ壁を越えるための避けられぬ壁だと強い気持ちを持って戦いに臨みました。
開会式
開会式は12/4 18:00、この時、僕は神妙な顔をしてPCと向き合い、開会式に向けて精神統一をしていた...
と、言いたいところですが、実際は7日に重要なプレゼンをしなくてはいけなかったので、7日の用事が終わるまではコンペはほとんどノータッチでした。
ちなみにコンペ開始直後に動きを見せずにじっと、さながら潜水艦のごとく様子を伺うこの戦法はサブマリン戦法と呼ばれ、人々を油断させて機を見て喉笛を喰らう戦法として古来から畏怖されてきました。参考文献
(なお、この間、僕はコンペのコードをほぼ書けなかったので別に戦略的な意味は全くありませんでした。)
プレゼン資料の細かいレイアウトの修正をしながら、開会式を見ました。コーヒーコンペがゲームの売上予測コンペに変わり、ゲーム好きな僕としては非常にテンションが上がりました。(コーヒーコンペも楽しみに待ってます。)
序盤(7日くらいまで)
実際はプレゼン資料はほぼ出来上がっていたので、コンペにガッツリ取り組んでも良かったのですが、僕は極度の対人恐怖症でプレゼンのことを考えると吐くレベルだったので、恐怖で頭が支配されていて深い考えを巡らす余裕がなかったため、簡単なベースラインだけサブミットして後はディスカッションを眺めていました。この時スコアは1.6969でした。(ちなみに評価指標はroot mean squared logarithmic error)
あまりコンペのコードを考える余裕はなかったので、ディスカッションを眺めていると、'Name'(ゲームのタイトル)から特徴量を得たい、といった旨のディスカッションが目につきました。
...気づいたらディスカッションを書いていました。Nameのembeddings表現から特徴量を得られないか検討 不安とは一体...(一応弁解しておくと、以前似たことをやったことがあったので、過去のコード資産からほぼコピペでかけるコードでした。)
(今回コンペの形式がopenだったぽいので、ディスカッションも貼れていいですね。atmaCupは日本語で良質なディスカッションから情報を得られるので、見れるものは一度覗いてみることをお勧めします。)
Nameのembeddings表現から特徴量を得られないか検討 について
せっかくなので、このディスカッションについて書いてみます。
本データには結構似たタイトルのゲームがありました。(というか全く同じものもかなりありました。別プラットフォームでの販売、リメイクなどなど)
個人的な感覚として、なんとなく似たゲームは似たタイトルになるよなと感じた点。また、同じシリーズのゲームのデータがあった点。これらを踏まえて、タイトルからゲームの傾向を掴めないかなーというのを、下記ディスカッションを眺めていて思いました。
以上を踏まえて、Nameのembeddings表現(いわゆるベクトル表現)から傾向を得られないかということをやりました。 ディスカッションに書いてあるので繰り返しになりますが、流れとしては、以下のことを目的としたディスカッションでした。
Nameのembeddings表現をBERTを使って得る。
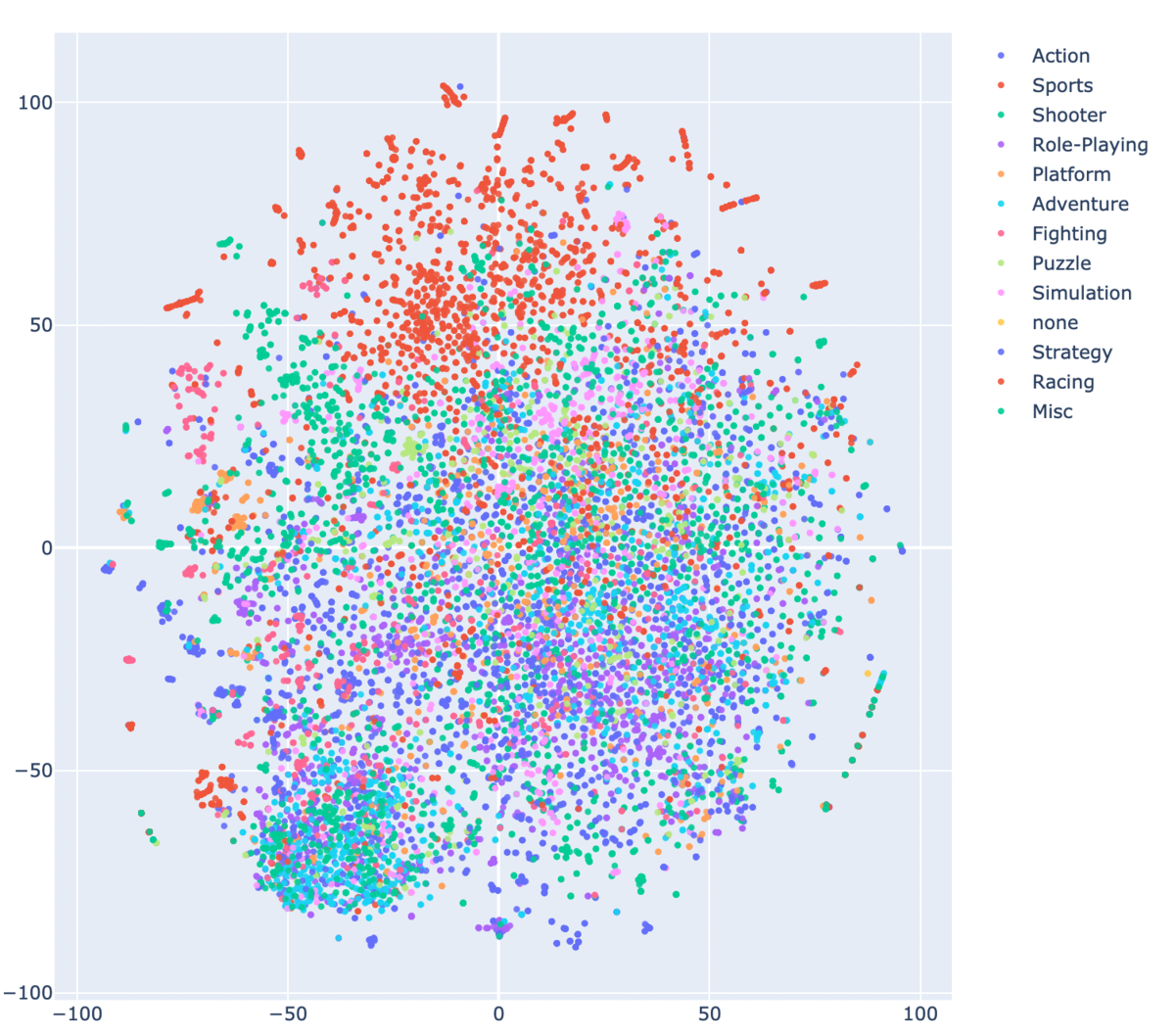
Nameのembeddings表現をtsneで2次元に次元削減する。
Plotlyで散布図として表示することで(ついでにジャンル別に色分けして表示することで)、何か情報を得る。
ご覧のように、スポーツなどは割と似たタイトルのものが固まっていてジャンルとして、うまいこと分けれるのではないかなという印象を持ちました。
t-SNEでの散布図 html
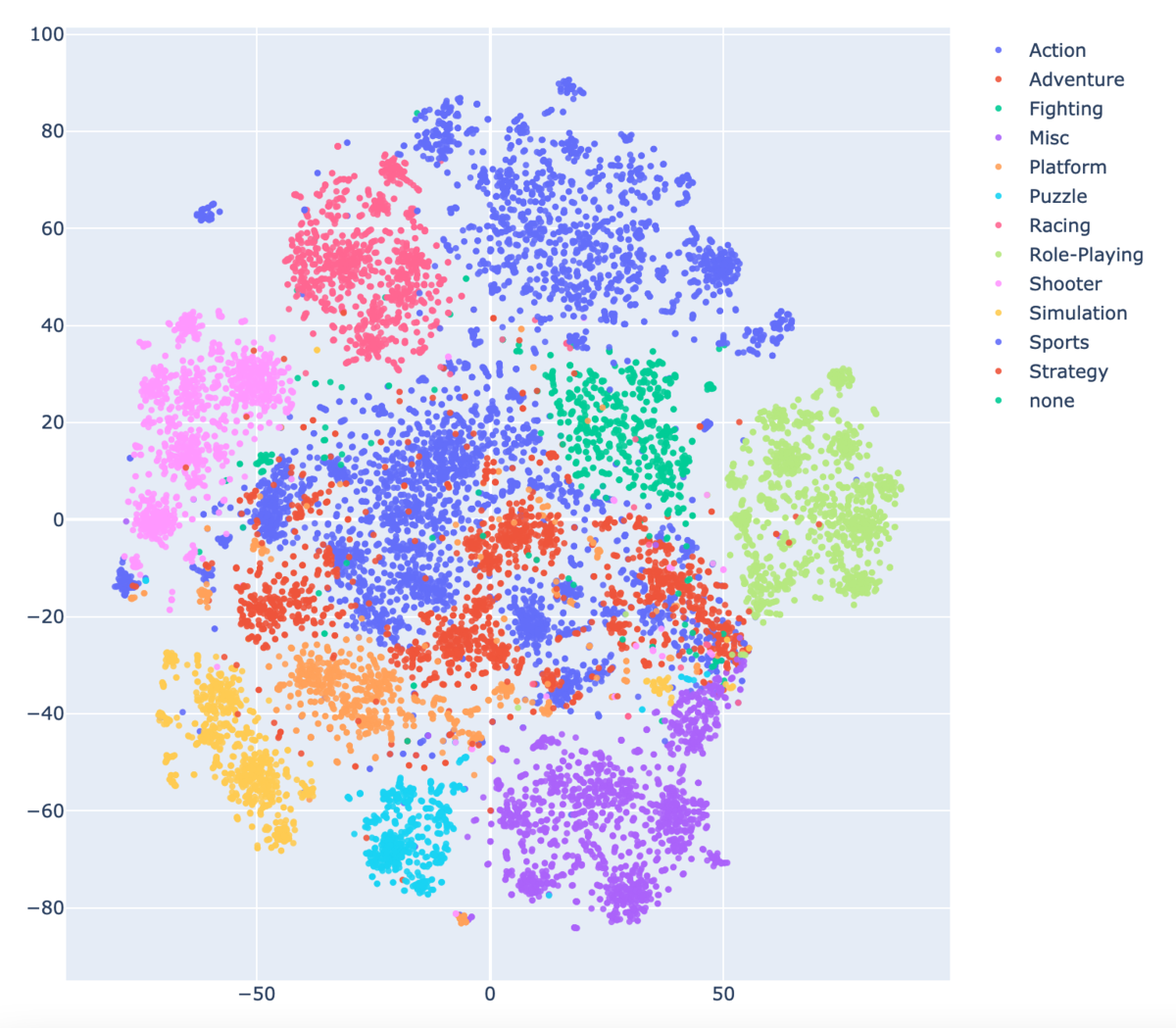
ちなみに、こっちはディスカッションには上げませんでしたが、Nameの前にGenreの情報を付け加えたもので得たEmbeddingsで作成した散布図はかなり綺麗にGenreごとに分かれました。
このことからタイトルからジャンルを推測はできそうだなという感想を持ちましたが、ジャンルの予測をしたい状況が生まれなかったので、これはそこまで役に立ちませんでした。(後にも書きますが、これら2つのEmbeddingsをt-SNEで得た二次元の情報はfeature importanceでそこそこ上位につけていたので、全く役に立ってないわけでは無いです。)
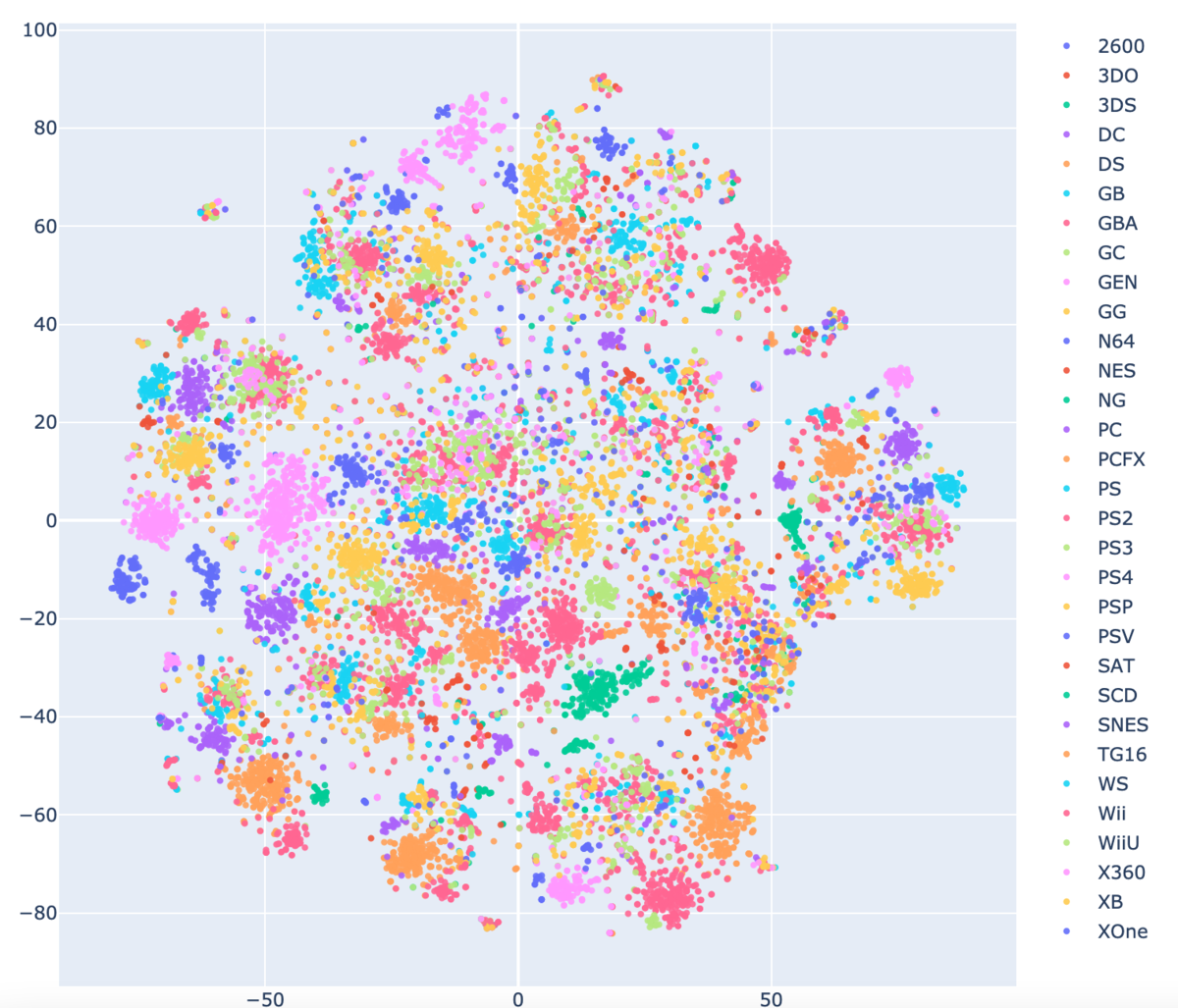
おまけですが、Platform+NameのEmbeddingsをt-SNEかけたものは、ここから情報を得るのちょっと難しいかなという感想を得ました。同タイトルでプラットフォーム変えて販売したりしてるのでそれはそう。
8日〜10日 0.9の壁
7日の重たい用事が終わったので、ここからはフルコミットで取り組みました。 一般的な特徴量を色々つくりました。
作った特徴量を大雑把に紹介
カウント/ラベル/ワンホット/ターゲット 各種エンコーディング
まぁ普通にそれなりに効いた。(ターゲットエンコーディングはそんなに効かなかった気も、一番カウントエンコーディングが効いてた印象)
Platform+Genreを文字列として結合してカウントエンコーディング
プラットフォームごとに流行りのジャンルとかありそうだなと思ってやった。効いたような効いてないような。
Platform+Genreを文字列として結合、追加でYearをビニングしたものも文字列として結合してカウントエンコーディング
プラットフォームごとに流行りのジャンルが年毎にありそうだなと思ってやった。そこそこ効いた。ちなみに5年単位でビニングした。
Name、Genre+Nameの2種のt-SNEの二次元ベクトル
Feature Importanceではそこそこ上位にいたけど、あんまり効いてなかったような...? 実際、Nameの特徴量が売り上げにそこまで効きそうな感じしないし。
User_Scoreのtbdのフラグ
User_Scoreにtbdという、おそらくTo Be Determined (現在未決定だが、将来決定する)を意味する文字列が、欠損値とは別に相当数あった ちなみに、対して効かなかった。
Platform・Genre・Ratingごとに各種売り上げ['EU_Sales','Global_Sales','JP_Sales','NA_Sales','Other_Sales','Global_Sales']の平均、最大、最小、合計を計算
無難に効いた気がする。ただ、ここら辺の情報を使うのはリークが怖かった。
PlatformのPublisher数、Developer数、Genre数、User_Count数をカウントしてplatformの人気度?的なものを考慮
そんなに効かなかったぽい。(feature importanceを見る限り)
Platformが発売された年度の作品かどうか
ローンチタイトルは売れるんじゃね?みたいなディスカッションがあったので、参考に追加。そんなに効かなかった。
発売してからの経過年数
発売してから時間が経つと、人気も少しずつ上がっていって(一般家庭に普及して)ピークを迎えたら、その後目減りしていくだろうなと考えて作成。結構効いた気がする。個人的に割と他の人は作らなかった特徴量として差別化になるのではないだろうかと思う。
User_Score x User_Countでユーザーがつけたスコアのサム
User_Scoreがかなりfeature importanceで上位につけていたので、これをもっと活かせないかと考えた。結果結構効いた(feature importance上は)。
PublisherとDeveloperが同じか違うかのフラグ変数
パブとデベが一緒だと無難なゲームになりがちで、違う場合はデベが意欲作を出していて、売り上げがバラつくんじゃないかと予測した。trainのデータでしかないが、実際に同じだと安定した分布で、違うとばらついてる様子がみて取れると思う。ただ、feature importance上位には出てこなかった。ちょっと効いた気もするがそこまで効かなかった。
長々書いたけど、だいたい作成した特徴量はこんな感じ。
モデル
安定のLightgbmと、途中からcatboostを混ぜた。 ただ、catboostのターゲットエンコーディングは使わなかったので(処理を書くのがかなり面倒だった(効くのか自信がなかったし))、どこまで混ぜた意味があったか疑わしいものである。
ちなみにoptunaつかったんだけど、全く精度が上がらなかったので、初心者向け講座で使われてたパラメータをずっと使い続けてた。
ここまで
ここまでやって、なかなか0.9の壁を破れなかった。当時のTwitterからも苦戦している様子が窺える。何か壁を破る飛び道具が必要だなと考え始める。
ぐ、ぐぎぎぎぎぎ... pic.twitter.com/uy0Fi0cfWU
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月10日
Publisher == "Unknown" のデータに対する考察
何を思ったか、ディスカッションを立ち上げる。Publisher == "Unknown" のデータに対する考察
何か策は無いかと、データを眺めているとPublisher=="Unknown"のデータに明らかに、パブがUnknownではなさそうなデータがいくつか見つかった。意図的にPublisherをUnknownにして、trainとtestでPublisherが被らないようにしている可能性があるんじゃ無いかなーと思ってディスカッションを立ち上げてみた。(最初は、僕の好きなSubnauticaというゲームが"Unknown Worlds Entertainment"開発なので、聞いたことないけどそんなパブリッシャーもあるんだなーとあんまり気にしてなかった)
Publisher=="Unknown"の例:
- "Nintendo Puzzle Collection"
- "Mega Man X Collection"
- "Persona 5"
- "Final Fantasy Type-0"
- "Afrika"
コメントでもいただいていたが、ここら辺外部データの使用にもなりそうな気もしていたので、どうかなーと思ったが、ギリギリセウトだろうと思ってディスカッションにしてみた。というか一人で抱えておいて、後からダメですと言われる方がつらいと考えた。
(参加してなくてあまり事情を知らない人向けに書くと、据え置きかどうかも外部データ扱いでフラグ変数に与えるのは無しでと言われていたというのもあったりしたので、ここら辺割とかなりグレーで運営を困らせていた可能性はある。すみませんでした。)
後でもちょっと述べるけど、ここら辺の特徴量は僕は使ってない。(いや、UnknownをNaNにするのを試したりしたので使ったといえば使ったかな。)コメントでも書いたけど、Publisherを予測なんてできないだろうし、運営の意図が見えてちょっと面白いかなくらいの気持ちでディスカッションを書いた。
神ディスカッションとの出会い
最終的にベストディスカッションに輝いた[update]atma8の進め方を考えてみた(ドメイン特徴量, Publisherの扱い方など)をよく読んでみると中に、Publisher、Developerにpivot_tableを作ってPCAをして特徴量を作成するといった旨のことが書いてある。これを使うことで、0.9の壁を破ることができた。本当にありがとうございます。
やったー、やっと0.9の壁を破った!
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月11日
Nice Hard Work ✒ 現在の順位は 22位です. https://t.co/Hq1WFLId3S #atmaCup pic.twitter.com/Wnl3msXyGo
ただ、このPCAで一気にスコアが伸びた理由について正直いまだに腹落ちしていない。コメントも見てみたけど、いまいち納得できていない。ここは勉強が足りていない部分である。
瞬間最大風速
この後、 発売回数(プラットフォームで分散の可能性)、別の年に発売されたかどうか(リメイクされたかどうか)などの特徴量を加えて、瞬間最大風速、敢闘賞で12位、全体で14位を記録する。
ちなみに、この後は色々やってもスコアが上がらず、相対的にどんどん落ちていく...
刻んでゆく
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月11日
Nice Hard Work ✒ 現在の順位は 12位です. https://t.co/Hq1WFLId3S #atmaCup pic.twitter.com/AMeADOC3x7
さいご
最終的に敢闘賞で26位、全体で30位になった。4位分シェイクダウンしてしまったのだが、ベストサブをきちんと選べているので、単純に他の人が上手だったということになる。 目標の一つだったTOP 15%には入ることができたので、非常に嬉しく思っている。その一方でもう一つの大目標、入賞して物理メダルをもらうは達成できなかったので、その点は非常に残念ではある。しかし、これで初心者の壁を少しは越えることができたのではないかなと思っている。どうかな?みんな?
#6 Sansan × atmaCupで何もできず己の無力に泣いたあの時の雪辱は返したぞ、あの時の僕よ。
今回のコンペに関して
今回のコンペではいくつかの流れがあったと思う。それに対して、ちょっと書いてみる。
trainとtestのPublsher分布の違い
本コンペではtrainとtestのPublsher分布が完全に分かれていて、そのためバリデーションをどうするかという点が結構争点になったと思う。(これもあってPublisher=="Unknown"のディスカッションを上げた。結構コメントで盛り上がってくれて嬉しかった。)
正直、正解は今でもよくわかっていないのだが、僕はPublisherをStratifiedKFoldすることで、バリデーションごとにPublisherでの差が生まれないようにという意図を持って進めていた。ある程度相関は取れていたのだが、完全にリンクしているとは言えなかった。
Cross Validationについて(CV:0.796, LB:0.8828 → CV:0.871, LB:0.8823)
一度上記のシリーズで分割する方法も試したのだが、目立った改善がみられなかったので今まで使っていた安全牌に戻ってしまった。
結局、どうするのが上手いバリデーションだったのかは上位の回答をみても明確な答えはないように思える。
シリーズの特定
Nameのembeddings表現のディスカッションを書いておきながら、自分はあまりシリーズの特定には積極的ではなかった。ディスカッションの流れを見るに多くの人がこれに取り組んでn-gram使ったり、レーベンシュタイン距離を使ったり、単語の出現回数使ったりと色々工夫をしていたようだが、個人的にはシリーズの特定が売り上げにそこまでつながる気はしなかった。
というよりうまくシリーズの特定ができるのかというのが疑問だった。例えば例をあげると、"LEGO Harry Potter: Years 5-7"を"LEGO"シリーズに入れるか、"LEGO Harry Potter"シリーズに入れるかの判断は難しい。(ちなみにレゴハリーポッターはクソゲーです。)このように、シリーズをどう区切るかは人でも難しいところがある。
みんな、この点工夫して頑張っていたようだが、自分はNameのembeddings表現のt-SNEだけ突っ込んでシリーズ特定による特徴量は使わないことにした。 どこまで差が出たかは、分からないがどうだっただろうか。
リーク
このコンペを語る上で、これは避けられないだろう。ある段階から、1位のスコアが飛び抜けてよくなり、ワザップにatmaCupの裏技が乗ってるなど話題(ネタ)になった。
リーク内容の詳細については1位の人のディスカッションを読んでください。1st place solution
言われてみると確かに最初にデータをみた時に、Year_of_Releaseで綺麗に並んでるなーとか思った覚えがあるんだよなー、違和感に敏感になれる人間になりたいですね。
感想
どこかでみましたが、テーブルデータだと思ったら、自然言語処理だったと思ったら、時系列データだったというのが、このコンペを表している気がします。参加者ごとのレベル別にいろんな角度から見ることのできるデータでかなり面白いコンペだったと思います。
本当に初心者向けのコンペとして非常に出来が良く、初心者にはタイタニックよりもこれをお勧めしたいと感じるくらい非常に良かったと思います。最高でした!(次はコーヒーでバトル!(コーヒーじゃなくても次回も楽しみに待ってます。))
また、今回は2つディスカッションを上げることができて、意見交換できたり、Upvoteもらったりと非常に楽しくやれた。第二回での初心者向け講座で良いディスカッションがあると紹介してもらえたりと非常に嬉しかった。楽しい思い出がいっぱいですね。
最後に、1位のmagic featureでのlate sub
1位のmagic feature late sub部 pic.twitter.com/qB9eNGG4AG
— KEN(pop-ketle) (@ken7272popqjim) 2020年12月15日
全く整備してませんが一応Githubのリポジトリ貼っておきます。スターくれたら泣いて喜びます。(一度もらう経験をしてみたい。) GitHub - pop-ketle/atmacup8
大学生からの「取材学」-他人とつながるコミュニケーション力の育て方- を読んで
前置き
お勧めされたので、 大学生からの「取材学」 他人とつながるコミュニケーション力の育て方という本を読みました。
コミュニケーション能力笑と馬鹿にされがちなところがある、コミュニケーション能力ですが、これは実のところ万物に通じる最も汎用的な能力の一つです。 わざわざこのページをみてくださるような酔狂な方には、いうまでもないことかもしれませんが、人生で一番大切なことは伝えることです。
これは世間で広告屋さんが蔓延っていることからも理解できると思います。何かいいものがあってもみてもらう機会、伝える力がなければ存在しないのと一緒なのです。例えば、同じことを発表するにしても面白いプレゼンとつまらないプレゼンがあるものです。
私はこのことに就職活動を通じて身を持って分からせられました。自分の実績ややりたいこと、夢や目標、これらは全て持っているだけでは意味がなく達成した上で、誰かに伝える必要があるのです。
まあ、それはともかくとして。本書は、取材を通して「伝えること」をメインテーマに据えています。不思議に思うかもしれませんが「聞くこと」ではないです。
取材を通して、自分が感じたもの・得たものを伝えていく力・技能について書いた本だと思っています。でも、あまり特別なことは書いてないようにも思います。相手に誠実に、実際に会って向き合うことが大切など、他者を少しでも理解するための技術...というか筆者が心がけているノウハウ的なものが書いてあります。
こう書かれるとよくある薄っぺらい意識高い系の本に思えるかもしれませんが、中身はかなり重いものです。
それは、筆者の持つ来歴からくるものでしょう。筆者はノンフィクションライターとして、世間を騒がせた多くの事件「オウム真理教事件」や「女子高生コンクリート詰め殺人事件」などと直接関わってきています。そうした人の口から語られる「取材学」についてのノウハウ、というより経験は軽いものでは決してありません。
筆者の書いた本の序章、第一章、第二章部分が下のリンクから読めます。これを少し読んでみれば、この人の口から出る言葉が決してコミュニケーション笑などという軽いものではないということがわかるでしょう。
【連載】17歳の殺人者 第1回 目次
暗い話はここまでにして、この本で僕は2つ特に面白いなと思った点があります。
それは、以下の二点についてです。
- 入れ替え可能性
- マイ目利き
入れ替え可能性
入れ替え可能性とは、これをやるのは自身じゃなくていいんじゃないか、もっと他の人なら自分よりうまくやれるんじゃないだろうか、自分は他人と入れ替えられるのではないかという考えのことです。
これを読んでくださる皆さんは、こんなことを思うことはあるのでしょうか?この気持ちが万人に共通なものなのか私には判別がつきませんが、僕はよくこのことについて考えます。
研究をしているから、新規性についてつい考えてしまうためなのでしょうか、最近は特によく考えます。自分がやっている研究なんてもっと強い人がやったらすぐできちゃうような自明なものなんだろうなと(そしてその感覚は間違っていないように思える)よく考えます。
筆者は何人もいる取材者の一人に過ぎない身でありながら、何を持って自分を他と違うものとするのかという問いに、紛争地帯で実際に体験した経験からこれを今伝えられるのは自分しかいない、そんなものがあると考えるようになったそうです。
翻って自分はどうでしょうか、正直上位互換がたくさんいるように思えます。まだしばらくはこの入れ替え可能性に悩まされることになるのでしょうが、今この瞬間にこんなことをやっている(ある種暇な)人は自分しかいないのだろうという気持ちはあり、これは自分にとって一つ救いとなる拠り所です。研究で言うと、割とニッチなブルーオーシャンを、さらにニッチな角度から攻めている(と思っている)ので新規性自体にはことかかず、ありがたい限りです。
しかし、自分の上位互換がいるという考えはなかなか折り合いをつけるのが難しい問題です。自分は現在は、自分のやりたいことにとにかく目を向けることで、あまり気にしないようにしていますが、やはりこれは定期的に虚無感と共に自分に襲いかかってくる難問ではあります。
まだ、自分の頭のプールに考えが浮かんでいる状態止まりで、うまく言語化しきれていないので変な文になってしまいました。ここでやめておきます。
マイ目利き
これはたくさんの情報に溢れ、自分にとって必要な情報を見落としがちな現代において、ある分野について詳しい、自分にとってのマイ目利きを知っておき、動向をチェックしておくことで自身も最新の情報を得られるといったような話です。
これと同じような効果を僕はTwitterに期待していてその点で面白いなと思いました。
Twitter上で情報発信をしてくれている、もしくはただ日常を流しているだけのアカウントでも、その日常に触れることで先端のトピックに触れることができます。
Twitterいいですよね(は?)
本の中身についてちょっとだけ
最初の方だけ本についてメモを取りながら読んでいたので、これを捨ててしまうのももったいないので学んだことを書き残しておきます。
相手の話にピリオドを打たない
- インタビューは一方的に行われるものではなく、行きつ戻りつしながら、聞かれる側にとっても驚きを共有する豊かな場となり得る。
- まくらを投げる。
- 「要するに」といった整序された、平面的な言葉で語られることは、本質的な話を避けるために、不安からそういうことを言う。
- ラベリングをしない。
- 型にはまった結論を導き出すことによって、聞き手がカタルシスを得ようとしない。
「知らないこと」より「知ろうとしないこと」が恥ずかしい
- 自分が知らないものは、知らないときちんと認めて知ろうとする。
知らないものを知っているフリをするのは相手にも失礼
反対意見を聞き出す知的好奇心
- リトマス試験紙のようなものに相手の言葉を浸して、自分と同じだと安心していた(この表現好き)
- 自分と反対する意見を聞くことはストレスになる。
筆者は、最初は反対意見は、それを主張する権利にも反対だという考えを持っていた時期があったようだが、討論番組に出て討論した後、反対意見の人と飲み会や雑談をするといった経験をしたことで、人間には全く別の面があり、その面白さに気付いたとのこと。 意外な一面や、逆から見た物事の捉え方、見方を見た時の知的興奮を面白く感じれるようになったらしい。
話を聴く「準備」が大切
準備
インタビューの目的と、何をテーマに話どういうトピックを軸に記事にするのか。インタビュー時間や、原稿量についても確認が必要。
下調べ
- インタビューテーマと、相手に対しての事前知識
- インタビュー場所にいく自分を安心させるための下準備
- 自分を納得させるため、気持ちに踏ん切りをつけるための行為
- 「相手に何を聴くか」も重要だが「どういう自分をそこにおくか」も重要
- 準備のしすぎもそれはそれで問題。
- ある程度手の内を見せる、「こういうことを聞きたいんですよと」枠を見せる
- 「私は知らないけど、あなたが知っていることを教えてください」というのが根底にあって、答え合わせ的なインタビュー、自己満足にはしたくない。
- 自意識=「自分のありようについてどう考えているか」
「聞いて欲しいオーラ」を見逃さない
感想
本全体としての感想は、取材・コミュニケーションとは、一方的に相手の話を聞くことではなく、自分から情報を与えていくことで、相互に理解を深めていく中で、お互いに今まで知らなかった発見をする場である、という考え方が根底にあると僕は受け取りました。そのためには、僕が普段から大事にしている相手に真摯な、誠実な態度で向き合うという考え方が大切であるとも書いてあります。
Team GeeksでいうHRT(ハート(HEART))の精神と似ているなと感じました。謙虚(Humility)、尊敬(Respect)、信頼(Trust)。結局のところ、人と人とのインタラクションにおいて最も重要なのはこの3つに尽きるのではないでしょうか?
とこんな感じでこの本の感想をまとめたいと思います。
おまけに。Team Geeksもかなりいい本なのでお勧めです。ピープルウェアとかのおもしろエッセイ本と比べてかなり実践的な本だと思います。(別にピープルウェアをディスってるわけではないですし、トム・デマルコさんの本は好きです。)
ProbSpace 対戦ゲームデータ分析甲子園(スプラコンペ)参加記(pop-ketle版)[最終順位97位]
はじめに
2020年8月19日(水)〜2020年10月18日(日)に開催されたProbSpaceの対戦ゲームデータ分析甲子園に参加してました。
OverwatchやR6Sなどチーム戦系のゲームはそこそこやっていますが、スプラトゥーンはやったことがなかったためドメイン知識は皆無でした。スプラトゥーンは用語が独特で正直辛かったです。
最終順位は大して高くないですが、自分の勉強になるので恥を忍ばず、取り組みを書きます。 あと、言ってしまうと上位30位くらいまではともかく、割と運ゲー感強めのコンペだったと思ってるので、この順位でも取り組みを晒すのは意味があると思っています。
コンペ概要
面倒なのでコンペページからそのまま引用してきます。
コンペティション概要
本コンペでは、オンライン大会があることでも有名なゲームの対戦データを用いて、勝敗予測モデルの開w発にチャレンジいただきます。
背景課題・目的
eスポーツは、2019年時点で既に$957.5M、2023年には~$1,600Mにまで拡大が予想されている急成長市場です
国内では任天堂・コナミといった企業が発売している、スプラトゥーン・ウイニングイレブン等が有名で、 スプラトゥーンにおいてはスプラトゥーン甲子園、プレミアリーグが開催されるほどの大きな広がりを見せています。
そこで本コンペにおいては、ある有名ゲームのオンライン対戦データを用いて、勝敗を予測するアルゴリズム開発にチャレンジいただきます。
学習データの中には、ステージ、武器、ウデマエ、レベル、勝敗といった情報が含まれております。 対戦を優位に進めるために、どの武器を選択すべきか、今後の対戦に役立てられるようモデル化できればと思います。 今までプレイ経験のない方も、ぜひこのコンペをきっかけに参戦いただけますと幸いです。
評価指標
目標は、テストデータセットのバトルの情報にもとづき、勝敗を予測することです。y(勝敗)を二値で予測してくだい。
評価指標
モデルの予測性能は評価関数accuracyで評価されます。
評価値は0以上1以下の値をとり、精度が高いほど大きな値となります。
取り組み
やったことを書いていきます。
前処理
ブキ関係
武器の名前を変換
ベッチューやらデコみたいな同じ性能で、違う名前の武器が存在しているので、全てオリジナルの武器名に変換する。ブキのelo-ratingを計算
フォーラムの実装を元にして、モード別+全モード合計のelo-ratingを計算する。 これをメインブキ、サブブキ、スペシャルごとに行う。ブキのカテゴリー1(メインカテゴリー)ごとのチーム別出現頻度
フォーラムのスプラコンペ 勝率検証EDAにて、チャージャーが偏ると弱いなどの知見が得られていたので、チームごとにどのタイプのブキでチームを構成しているかを、出現頻度の特徴量を作成した。 実際にFeature Importanceでもチャージャーのカウント数は特徴量として寄与度が大きかったのでこれは効いていたと思われる。ランクごとの武器の出現頻度数を特徴量として、武器の使いやすさみたいなものを特徴量とできないだろうか
高ランクほど強い武器を使いがちや、高ランクの人しか上手く扱えないブキのような情報を入れたかった。
モード別、モード関係なしで分けてそれぞれでブキの出現頻度をランクごとに出すことで、ブキの使いやすさ的なものを考慮できないか試した。Feature Importanceはそこそこ高く出てるけど、直感的にはそこまで効きそうなイメージは持てなかった。
レベル関係
レベルの最大値、最小値、合計、平均、中央値、分散、標準偏差
チームごと、2チーム合わせてそれぞれ計算して、とりあえず、レベルで手軽にできそうな処理は一通り行った。これは中央値とかが意外とFeature Importanceで寄与度が高かった。レベルが一番高い人/低い人
レベルが一番高い人/低い人がAチームにいるのか、Bチームにいるのか、どっちにもいるのか(例: レベル84が全体で一番レベルが高くて、かつどっちのチームにもレベル84の人がいる)この3つに分類する特徴量を作った。これをターゲットエンコーディングしたものがFeature Importanceで寄与度が高かった。A/Bチームの最大レベル - B/Aチームの最小レベル
ちょっと言葉は悪いが、チーム戦のゲームではキャリーしてくれる人と、お荷物枠みたいなものが言われることがあり、最大レベル - 最小レベルのレベル差の特徴量を作ることで、どっちのチームにキャリー枠/お荷物枠がいるのかを考慮できないか考えた。 これはFeature Importanceで寄与度が高かった。
ステージサイズ
- ステージサイズの情報
外部データのステージサイズの特徴量をそのまま加えた。
これにプラスして、ステージサイズがデカければチャージャー系が役立つなどが考えられたため、平均との差をintに丸めて特徴量とすることで、平均よりステージのサイズが大きいかどうかを考慮させようとした。 平均との差を入れて精度がちょっと上がった気もするが、Feature Importanceは確認してないのでどこまで寄与したかは知らない。
その他
各特徴量に対して、ワンホットエンコーディングやらラベルエンコーディングやらターゲットエンコーディングやら色々なエンコーディングを試してみた
今回のコンペ、ターゲットエンコーディングに一番時間をかけたのだが、振り返ってみると、結局ターゲットエンコーディングはあまり効いてなくてワンホットとかが一番効いていた感じはあった。モード別学習
フォーラムでも出たが、モード別に学習モデルを分けた場合の結果(参考)lobby-mode別に学習した場合の結果モードを分けて学習させることを考えていた。
割と有力なアイディアだったのだが、publicでのスコアが0.548906と結構落ちたので、元々ナワバリは予測しやすいのから分けると精度高く出るように見えるだけで、結局合計すると結果は変わらなくなるのではないかと考えて使わないことにした。(余談だがprivateでは結局一番のスコアを出した。)
作成したモデル
とりあえずシングルモデルで
Lightgbm(binary_errorを目標指標)
CV: 0.550くらいLightgbm(binary_loglossを目標指標)
CV: 0.553くらいcatboost(デフォルトパラメータ)
CV: 0.552くらいcatboost(optunaで最適化)
CV: 0.547くらい(optuna使うとデフォパラメータより精度が落ちた)Entity Embeddings
フォーラムの実装そのままEntity Embeddings + MLP による実装および質問(LocalCV: 0.5454 PublicLB:0.5517)
これらを実装した。
ランダムフォレストとロジスティック回帰も試していたが、ランダムフォレストはあまり精度が向上せず、めんどくさくなったので途中で使わなくなり、ロジスティック回帰は精度が高いなと思っていたが、よくよくみてみると1ばかり出力してtrainのデータが1が多めだから精度が高いだけぽかったので使うのをやめた。
これらをランダムシード10 x フォールド数5の計50個のモデルを作成して、stackingしてaveragingしたものを提出してコンペを終えた。(ちなみに、public: 0.554975 でpublicのベストサブではなかった)
最終的にpublicでのベストモデルはlgbmだけで平均アンサンブルしたものでpublic: 0.556528だった。
今回のコンペは全提出がprivateでも評価されるものだったので、目立ったモデルをいくつか上げる。
ランダムシード10 x フォールド数5の計50個のモデルを作成して、stackingしてaveragingしたもの
public: 0.554975、private: 0.548906lgbmだけで平均アンサンブルしたもの[public best]
public: 0.556528、private: 0.546460lgbmだけでモード別に学習させたもの[private best]
public: 0.548906、private: 0.552294
二つしかサブを選べなかった場合、上の二つを選んでいたのでルールに助けられたと言えなくもない。 とはいえ結局、public: 81位、private: 97位とshake downしてるので、他の人が受けた恩恵のほうが大きそうだが。
感想戦
2nd Place Solutionについて
2位の人の効いた特徴量について(Public3位、Private2位)での
- プレイヤーが2時間の中で同じ武器を何回使ったか
- プレイヤーが2時間の中で何個の武器を使ったか
で、プレイヤーの調子を考慮するというのは素直になるほどなあという感じで感心しました。
とはいえこんな感じなので、自分では一生でなかったアイディアです。
武器変更はなるほどなーという感じだけど、別ゲーだけど自分は割とキャラやら武器カチャカチャ毎試合変えるので、いくら時間かけても自分では思いつかなかっただろうな
— KEN(pop-ketle) (@ken7272popqjim) 2020年10月19日
特徴量を加えるほど下がるCV
途中まで実装がバグってたのか、特徴量を加えるほどCVが下がる悲しい現象に1週間ほど見舞われていました。気合入れて特徴量作成含めて、実装を1から作り直したら、精度が上がり始めたので助かりました。 やはり心を込めた手作り特徴量は大切ですね。(は?)
昨日の真心込めて、1から作り直した温かい手作り特徴量のおかげで、スプラコンペのLBを167位から72位までぶち上げた
— KEN(pop-ketle) (@ken7272popqjim) 2020年9月18日
フォーラムへの参加
今回は結構フォーラムへの積極的参加も心がけていました。自分の存在が他に人の役に立ったかは知りませんが、データを探索するということに関して、他の人と話しながらデータについて考えられたのは僕はすごく楽しくてよかったです。
A1プレイヤーについて
A1プレイヤーの特定についてフォーラムで上がっていました。自分は扱うのが面倒そう(ドメイン知識がないため、レベルアップに必要な試合数の肌感覚がなくあんまり信用できなさそう)、かつあまり直感的に予測に効いてくる気がしなかったので早々に使うのをやめてしまいましたが、この情報を生かして何かうまい特徴量を作った人がいるのかすごく気になります。
ブキのDPSの細かい値について
外部データとして上がっていた、ブキのDPSの細かいデータについても、使うのが面倒そう、かつ使用可能範囲が割と曖昧で手をつけたくなかった(もっと言ってしまうと、自分でスクレイピングするなり、コピペするなりしてのcsvファイル作成をしたくなかった)ので触りませんでした。これらが効いたのかも気になります。
個人的には流石に細かすぎて、あまり効果はなさそうだよなと思っていましたが...?実際はどうだったのでしょう?
もう少し詳しく書くと、FPSではダメージ1の差でキルに必要な弾数が変わってきたりして、DPSも重要だとは思うのですが、スプラトゥーンは武器の種類で情報の雰囲気?が結構違っていたのと、あんまりルールを理解できていないため何が重要なのかよくわからなかったので上手くいかせなさそうだなと思って触りませんでした。(例えばキルフレーム(ヒト)、キルフレーム(イカ)のヒトとイカの違いが分からなかった。)
ブキの強さの尺度はelo-ratingで入ってるはずだからそれで十分かなと思ったのもあります。
まとめ
カテゴリカル変数ばかりで、そこからうまいこと順序をもたせた特徴量を作るのが難しいなという感想を持ったコンペでした。 ゲームの方でマッチングの勝敗が五分五分になるようにマッチ組んでるはずだから勝敗予測なんて難しそうだし、くじ引きコンペだろと正直思っていましたが、やはり上位30くらいまでは安定して上位にいられるモデルを組んでる方が多く、さすがだなという感想を持ちました。
途中、結構長い時間をターゲットエンコーディングの調整に割いたのですが、これがあんまり効かなくて取り組みとしては失敗だったかなという気はします。とはいえ思いつく特徴量も時間内に実装できそうな範囲ではやり尽くしていたので、これが自身の現時点での限界かなという感じで上位との壁を感じたコンペにもなりました。
やはり特徴量作成は大切なので、もっと引き出しを多く持ちたいなと思いました。
完
今後はしばらくatamCupで頑張りつつ、論文書くのと発表の準備を進めていきます。
正則化: 鋭すぎる刃物を鈍らせて使う
この記事何?
正則化について自分なりにまとめる。
はじめに
機械学習をかじったことがある人なら、正則化(regularization)という言葉について「聞いたことがある!」という人は多いだろう。ただ、この概念、個人的にあんまりピンとこないなという思いを持っていた。
なんか知らんけどとりあえず入れとくと上手いこと仕事してくれる便利なやつ、そんな感覚を持っていた。
そんな折、下記の本を読んだ。(厳密には読んでいる最中)
カーネル多変量解析―非線形データ解析の新しい展開 (シリーズ確率と情報の科学)
この本の中に、タイトルの「正則化: 鋭すぎる刃物を鈍らせて使う」という章がある。この章名をみた時、目から鱗が落ちるとでも表現すべき体験をした。
そんな自分の体験を新鮮なうちに少しメモしておきたい。(いや、ここ読んだの数ヶ月前なんですが...新鮮とは一体...)
正則化って...
まず、そもそも正則化ってなんなのか。とりあえず過学習を抑えるための手法だという説明を受けることが多いと思う。
一般的にパラメータの次元(数)が増えると、関数の表現力が上がりすぎて汎化性能が落ちる。これを次元の呪いやら過学習やら呼んだりする。つまり、パラメータの次元は必要最小限に抑える方がいいのだ。 計算時間を考えてみても、これはその通りであるということは理解できると思う。
次元の呪いって...
そういえば、正則化について考えてみる前によく考えてみると、次元の呪いという言葉もいまいちよくわからない。次元が増えると計算時間が爆発的に増えるとか、過学習しやすくなるとかそういう話はわかる。
しかし、よく次元の呪いの話について話すときにされる超球の話、これの意義がよくわからん。ちょっと調べてみた。
高次元の球では、ほとんどの部分が球の表面付近に分布する
この説明で、なるほどとなるやつがいるのか?...いるんだろうな、自分の無能さが悲しくなる。まあそれはともかくとして、ここら辺のリンクを読んでみた。
次元の呪いとは結局何なのか? - Qiita
次元の呪い、あるいは「サクサクメロンパン問題」 - 蛍光ペンの交差点[別館]
次元が増えれば表面積も増えるのだから、体積と半径が固定なら、そりゃ表面に体積が集中してくという話はわかる。なるほど、面白い現象かもしれない。
で?結局この超球の話をして、次元の呪いについて何を言いたいのか?
この問いに関して、僕は明確な答えを持っていない。高次元では非直感的なことが起こるんだよという話をしたかっただけなのかもしれない。よくわからん。
でも多分そうなのだろう。
つまり、少し話が脱線してしまったようだ。
今回の話で次元の呪いというときに、この超球の話を思い出す必要はなさそうだ。気になって調べてみて無駄に時間を使った。
結局、次元の呪いとは一つの現象のことだけを指すのではなく、
- 超球の表面に体積のほとんどが集まることとか
- 計算時間が爆発的に増えるとか
- 過学習しやすくなるとか
その他いろいろ、次元が増えたことで起きる面倒くさいこと・不思議なことをまとめて次元の呪いなどと仰々しい名前で読んでいるっぽい。
今は、次元が増えると計算時間が爆発的に増えるとか、過学習しやすくなるとかの問題があるということにだけ注目することにしよう。
正則化について立ち戻る
正則化とは、過学習を抑えるための手法だというところはいいだろう。 では、どうやってそれを達成しているのか考えていこう。
自分の持ってる直感的な理解としてはノイズを付け加えることで、過学習を抑えロバスト性を上げる。というのが一番近い。まさに「鋭すぎる刃物を鈍らせて使う」だ。
じゃあ、正則化項はなんでもいいのかというとそうではない。できれば、過学習したときにそれを咎める仕事をしてくれるものを考えたい。
一般的に、機械学習は正解ラベルと予測ラベルの誤差を最小化することを目的とするということは知っていると思う。
よく使われる最小二乗法の式でいうと
$$ C(x) = \frac{1}{n}\sum_{i=0}^n(y_{i} - f(x_i) )^2 $$
これを最小化する。ここで、$C(x)$はCost functionの意味、$y_{i}$は実際の値、$f(x_i)$は予測値とする。
正則化項にも種類があるが、メジャーなL1正則化はL1ノルムに係数$\lambda$をかけた項と言われる。
式にすると
$$ \lambda \sum_{i=0}^{n}|w_{i} | $$
となる。
この式はなんなのかというと、$\lambda$はハイパラメータで自分で調整する定数、$w_{i}$は予測値を出すときに勾配降下法で調整される重みである。勾配降下法については、機械学習をかじってれば、知ってる気がするのであまり説明しないが、微分してその傾きをみることで最適解を見つける手法だ。
で、この正則化項について話を戻すと、この$\lambda$を各重みのノルム(絶対値)にかけているということになる。
すると何が起きるかというと、$\lambda$が大きければ大きいほど、小さくしたいはずのコスト関数の値が大きくなる。大きくなると困るので、これをなんとかしようと重みが小さくなる方向に学習が進んでいく。
この重みが小さくなると何が嬉しいのかと、始まりの最小二乗法に立ち返って考えてみる。この式では、重みが大きいほど各変数(特徴量)の値が大きくなる、つまり過学習する方向に働く。L1正則化はこれを抑制しているのだ。
結論
まとめると、最小二乗法のようなコスト関数に正則化項を付け加えることで、各変数に対する重みが大きくなりすぎてオーバーフィットするのを防ぐための正則化の仕組みを説明した。
この正則化がどうしてうまくいくのかを、自分のできる限りで直感的に説明したつもりだ。
どうだろうか、「鋭すぎる刃物を鈍らせて使う」という言葉がしっくりきたのではないだろうか。(こない場合は僕の説明が下手なだけなので、カーネル多変量解析―非線形データ解析の新しい展開 (シリーズ確率と情報の科学)を買おう。すごくいい本なので(いつか読み終わったらレビューみたいなのも書きたい))
SIGNATE Student Cup 2020【予測部門】参加記(pop-ketle版)
これ何?
タイトルの通りです。SIGNATE Student Cup 2020に参加したので感想・学んだことを書きます。 色々学びました。辛いコンペでした。
SIGNATE Student Cup 2020って?
データ分析のコンペです。今回は英語の求人情報を4つに分類するというタスクのコンペでした。
①データサイエンティスト(DS)
②機械学習エンジニア(ML Engineer)
③ソフトウェアエンジニア(Software Engineer)
④コンサルタント(Consultant)
この4つです。
評価指標はF1scoreでした。 与えられたデータは求人情報のテキストオンリーです。これだけを使って分類をします。
どんなデータだったのか
どんなテキストか直接例をここにあげると規約的にやばいかもしれないので、テキスト例が乗ってるフォーラムを上げておきます。 SIGNATE Student Cup 2020【予測部門】 | SIGNATE - Data Science Competition
フォーラムを見てくれた人は分かったと思いますが、与えられたテキストは、本当にこんなんで予測できるのか?みたいなテキストでした。少なくとも私はそう思いました。おそらく求人情報の最初の一文だけ抜き取ったんじゃないか、そのくらい何ともいえないテキスト群でした。フォーラムにもあるように同じ文章で別の正解ラベルのものすらありましたし。 スコアとしても最終スコアの一位の人が0.5038085です。そのくらい分類するのが難しいタスクだったと言えるのではないでしょうか。
また、このタスクの一番特異な点として最後までフォーラムを盛り上げていたものに、trainとtestの正解ラベルの分布が明らかに違うというものがありました。 pandas-profilingの結果ですが、trainはこんな分布でした。

それに対して、testの分布はクラス数が1~4まで順にこのように予測されていました。[404, 320, 345, 674]
これも過去フォーラム参照SIGNATE Student Cup 2020【予測部門】 | SIGNATE - Data Science Competition
とまあ、少なくともtrainとtestの分布が違うのは明らか、そこからPublicとPrivateの分布がどうなってるのか不明という、何とも運要素の高いコンペだったと思っています。(もちろん上位はちゃんとshakeしないモデルを組めてるのですが) ここら辺はSIGNATEの決まりなので仕方ないのですが、kaggleみたいに最終サブを2つくらい選べると良かったなあとすごく思っています。
自身の結果について
なんで上でそんなに愚痴ってるのかというと、今回僕がものすごくshake downしたからです。 多分一番順位落としたんじゃないかな?調べてないけど。
順位としてはこんな感じでした。
| 暫定順位 | 最終順位 | 暫定評価 | 最終評価 |
|---|---|---|---|
| 36位 | 156位 | 0.4739678 | 0.4032951 |
暫定順位はサイトとして出るわけではなく、僕が23:59分に最後に確認したのがこうだったという意味です。
いやー、非常に辛いものがありました。瞬間最大風速7位だったので、結構夢を見れたのですが、そこから2週間色々試せど試せど思うようにうまくいかず何の進歩も生み出せず、ただただ順位が下がり続け、しかも最後に大幅なshake downと辛い戦いでした。色々疲れてもいたので、1日ほど寝込んで今この記事を書いています。
ちなみに自分の持ってた提出の中で最も最終評価が良かったのはこれです。
| 暫定評価 | 最終評価 |
|---|---|
| 0.4400458 | 0.4548169 |
正直、一つしか最終サブ選べない状態で0.03もスコアが下がるこれを選択はできないよなーという感じです。これを選んでいたら50位入るかなーという感じですね。とはいえ選べなかったので言っても仕方ないですが。 後ろの方で書きますが、コードで大きな失敗をしていたので、CVも信用できずこれを選ぶ選択肢にはどうしてもならなかったんですよ。
自分について
コンペ参加はこれが2回目で、かつNLPは全く触ったことがない、という状態で参加しました。一応bag of wordとかtf-idfとかword2vec、bertなんかの用語の存在くらいは知っていましたが、実際それらがどんな意味を持つものなのかはそんなに詳しく知らない。そんなレベル感で参加しました。
今回のコンペ参加で感じたのですが、NLPコンペってもしかして、BERT系のSOTAな優れたモデルをガチャガチャして、テキストの良い感じの分散表現を得るのが最大重要事項みたいな感じで、あんまり特徴量エンジニアリングの余地とかないんですかね。
tf-idfとか全く使いませんでした。いや、正確には初手LightGBMでtf-idf使ったモデル作ったんですが、次にフォーラム参考にして試したBERTが割と手軽に段違いで性能が良かったので、もうtf-idfとか時代遅れなんだなと思い込んで、アンサンブルに組み込むことすら考えませんでした。
あと、これも後ろでもうちょっと詳しく書きますが、前処理でちょっとごちゃごちゃやったらむしろスコアが落ちたのもあって(少なくともPublic LB上では)、前処理もなんか本当にやることあるのか?素人が下手に触らずにBERT様に任せた方が良いのでは?という感じでした。
このせいでモデルに汎用性が出なくてshake downしたんだろうなというのも今となっては感じているんですけど、まあそれは後の祭りなので。
マイソリューション
そんな僕の最終提出解法は、再翻訳したデータをBERTに突っ込むという単純なものです。再翻訳にはGoogle 翻訳のライブラリ?を使いました。これです。
from googletrans import Translator
有料らしいGoogle CloudのAPIは使ってないので規約違反はしてないはずです。 この再翻訳をドイツ、イギリス、フランス、日本語、韓国語と用意してそれぞれの言語データに対して、StratifiedKFoldでCVしたもので学習させて、最後に予測確率をf1スコアで重み付けしてみて平均とったものをargmaxしたという感じです。(後から中国語も作ったけど、提出したモデルには入ってない)
ちなみに後から、同じこと試そうとしたら再現性が出なかったんですが、これは一体...
これ作ったのがコンペ終了までまだ2週間もあるぞ!という、まだまだこれからスコア伸びてくでしょ!という希望に満ち溢れた時期だったので、あまり再現性とか意識せずゴリゴリコード上書きしてたんですよ。加えてGoogle colabで学習ぶん回してた関係上、今回Google Driveでそのままコード管理してたんで、変更履歴とかも残ってなくて...ちゃんとGithubとか使って、コードは管理するべきですね。学びました。
試行錯誤
そんなこんなあってできたここまでが僕の提出した解法です。
ここからは何の進歩も生み出せなかった、暗黒の2週間の間に色々試したことを、思い出せる範囲で書いていきます。
テキストの前処理
よくある小文字に変換するとか短縮系をなくすとかのやつです。
当たり前のようにPublic LB上ではスコアが落ちました。そのため、やはり細かいことは考えずBERTに直接突っ込んじゃった方がBERTがうまいこと処理してくれるのかなという考えを持ちました。
実際のテキストとして読む場合でも、短縮系とか使ってるのや、大文字小文字の違いは微妙なニュアンスの違いにつながってくると僕は考えています。特に英語圏は強調したい言葉を大文字で書くみたいなのはありますし。
過去の似たタスクのソリューション見ても、あんまりこの手の前処理をやったという話を自分では見つけられなかったので、やらない方が良さそうだなと思い、切り捨てました。
...ただPrivate LBを見てみるとPublic LBからスコアが上がってるんですよね。やっぱりある程度は効くんですかね?うーん...?
Pseudo-Labeling
ここら辺で、データに処理を加えるよりは単純に数を増やす方が良さそうだなと感じ始めたのでこのpseudo-labeling(擬似ラベリング)を試し始めました。
僕の理解している限りではこんな手法です。(間違ってたらどんどん教えてください。学んでる最中なので)
- とりあえず普通にモデルを作る
- 1で作ったモデルでtestデータを予測してラベルをつける、これが擬似ラベル
- この擬似ラベルデータからいくつかサンプリングして(train:pseudoが2:1くらいが良いらしい? (参考文献Kaggle State Farm Distracted Driver Detection - Speaker Deck))trainに混ぜ込んで学習を回すことで、擬似ラベルをリファインニングしていって、精度を上げていく
- 2~3を何度か繰り返す?(繰り返すのかどうかはよくわからない、計算資源やスコアの変化を見ながらという感じなのかな。あと、refineごとにモデルのウェイトの初期化を挟まないと過学習になる恐れがある)
これがうまくいく理由の直感的な理解として
- 精度の低めなラベル、つまりノイズの入ったデータが入り込みロバスト性が上がる。
- 単純にデータ量が増えるので精度が上がる
この二つが理由として挙げられるのかなと思っています。
これももちろんうまくいかなかったのですが、その理由としては元々スコアが低く出るタスク(f1で0.5レベル)だったために、あまりにも信頼性の低いラベルが入り込んでしまったというのがうまくいかなかった理由なのかなと思いました。
この方法はkaggle: Toxic Comment Classification Challengeではうまくいった方法らしいので (参考文献kaggle: Toxic Comment Classification Challenge まとめ - copypasteの日記)期待していたのですが残念でした。
(今見ると上の参考文献URLに下のように書いてますね。何で早く気付けなかったのか、いや、一次ソースのディスカッションのソリューションだけ読んでコメントまで見てなかったからですが...)
今回のタスクはスコアが0.98以上と非常に高く、疑似ラベルの信頼性が高かったことも影響しているのかもしれません。コメントにはスコアがそこそこのタスクで同様のことを試した際にはうまくいかなかったという経験談もありました。
ついでに書きながら思いつきましたが、上のフォーラムにもあるようにこのコンペに同じテキストがtrainとtestにまたがってある上、違うラベルが付与されてることもあるみたいなデータだったので、そのせいもありそうですね。
adversarial validation
TrainデータとTestデータの分布が異なる場合に有効な手法のようで、まさにこのコンペにぴったりじゃん!と思って試した手法です。(参考文献Adversarial Validationを用いた特徴量選択 - u++の備忘録)
これはデータがtrainかtestかどうかを分類するモデルを作り、trainの中のtestぽいデータの確率順にソートして上から順にvalidとして使うことで、テストっぽい分布のデータをバリデーションに使うという手法です。
これは結構分離する精度が良かったので、良さそうだなとと思ったのですが、提出してみたら、Public LBで0.4515126程度。しかもどうもvalidデータに毎回同じデータが選ばれすぎてる?みたいな過学習ぽい感じもあったので(ちょっとここら辺何言ってるのか分かりにくいかもしれないですが、ここら辺コードをバグらせていたのでうまく説明できないです、僕も何を言っているのかわからないです)、もう一つ精度が伸びないなという感じで使うのをやめた手法です。結局これも、暫定評価0.4515126、最終評価0.4173049でかなりshake downしているので、まあ使わなくて正解だったのかなという感じはします。
後から思うにここら辺多分コード、というか設計のバグが起因していたと思います。 というのも、もともと各言語のモデルを作ってアンサンブルするという手法だったのですが、あるときかから、なぜか再翻訳のデータを全部最初に合体させて一つのtrainデータとして扱うようにコードを書いてて、リークしまくりみたいな状態だったからです。(リークしないように工夫もしてたのですが、それがうまくいっていたのかはかなり微妙)
今思い返しても何でこんなことをしたのか、こんなことに長い間気付かなかったのか、全く理解ができないのですが、悪夢を見ていたからとしか言いようがありません。 色々試しても鳴かず飛ばずでかなり焦っていたというかストレスを感じて、早く新しい手法を試さなきゃという風に視野が狭くなっていたのでしょう、全体を俯瞰してみれる余裕が大切ということかもしれません。
roBERTa
roBERTaというBERTの派生系でほぼ完全上位互換と言っても良さそうなモデルっぽいものがあるということを知ったので、(自然言語処理知らないで割りと適当言ってるので、それは違うよという時は教えてください)これとBERTを足して二つのモデルをアンサンブルする感じで行こうかと思ったのだが、スコアとしては大体Public LBで0.44くらい、CVの結果を見てもroBERTaそんなに良い結果出てるか?という感じだった。というかむしろBERT一本の方が断然良い。これならBERT一本の方が良いかもしれんなPubilc LB 0.47で全然精度違うし。ということでroBERTaも試していたのだが最終的にはroBERTaを切り捨ててしまった。
これが汎用性という点で致命的なミスだったと言える。というのも、最終評価でスコアが比較的高めなやつは全部BERTとroBERTaのアンサンブルのやつだったからだ。 今回のコンペを通しての一番大きな学びは、モデルの汎化性能を上げるためには複数の種類のモデルのアンサンブルを積極的にやっていくべきというものである。汎化性能を考えると、多少(0.03が多少か?という話はあるが)精度が落ちていたとしても、複数のタイプのモデルを使ったものを選ぶべきなのだろう。自分の身に降りかかったものとして、このことをこれ以上なく強く実感できた。
...とはいえ現実問題Public LBで0.03もスコアが落ちていたモデルなので、今過去に戻ったとして、1つモデル選べよと言われても、このモデルを選べたかというと正直無理だろうなという気持ちはある。暫定スコアはもう見れないのでおぼろげな記憶でしか語れないが、0.47と0.44では順位が36位から70位近くまで落ちるはずである。複数のタイプのモデルのアンサンブルをしておくといいという知識があったとしても、1サブしか選べないのではこれを選べるかといえば無理だろうなと思う。そういうわけで、今回の結果は避けようのない結果だったと真摯に受け止めている。
その他細々とした取り組み
- t-SNE
センテンスの分散表現からk-NNあたり使って、似たテキストをくっつけたりとかできないかなと、t-SNEをかけて可視化しつつ様子をみたのだが、perplexity次第でどうにでもなる感じで、何ともいえない結果だった
小クラスタができてるといえなくもない気もしたのだが、上に上げたフォーラムにもあるように同じ(似た)文で違うラベルというのも相当数あるし、やっぱりこれを使ってもうまくいかないだろうなと感じたので信頼できず使うのをやめた。


- text generation
今回の与えられていたテキストが、募集要項の最初の一文のみ、みたいな感じだったのでテキスト生成で続き書けば良いんじゃね?と(悪夢を見ていておかしくなっていたので)考えて、試しかけたが、こんなの全く信頼できないだろと、我に帰ってテキスト生成するだけでやめれた。(逆にいうとテキスト生成まではしてしまった。)
- lgbm stacking
これも一応ほんとに最後の最後に試したけど、あんまり精度出ないなで終わりました。
まとめ
辛い辛いコンペだった。
自然言語オンリーコンペはコンペごとの取り組みの違いみたいなのが生まれにくく、SOTAなモデルをガチャガチャして精度出す感じで、あんまり面白くないのかもしれないなと正直なところ思ってしまった。逆にいえば、一度知識を得てしまえばあまり苦労せず安定して好スコアを出せるのかもしれないが。
コンペとしては面白くないのかも知れないけれども、自然言語処理自体には依然興味はあるのでそこら辺は悪しからず。
後そろそろチームを組んで議論するという経験をしてみたいものですが、何とかチーム組めたりしませんかね... 今回のコンペも色々コンペ中に話し合いたいことあったんですよね... 基本独学でやってるもんで、なんか今やってるのが正しいことなのかわからないのがすごい精神にきます...
色々学ぶことはありました。
学んだこと
そもそもNLPについて
NLP、ノー知識だったのでHuggingFaceのTransformersやらライブラリの存在を知れたこと。いろんなモデルがあるんだということ。あまり勉強間に合ってないけど、attenstionとかの存在を知れたこと。
ただ、NLPについてはまだまだ全く分かりません。今回初めてNLPの処理にこんなにGPU資源が必要だということを知りました。また、自然言語処理は分野として面白いけど、この方面にキャリアを進めていくのは茨の道になりそうだなということも感じました。というのも近年発展が凄まじいし、正直自分が何かやらなくても自分よりすごい人がどんどんやってくれる分野だろうなと感じました。実際今回の僕はBERTにタダ乗り状態でしたし... 未来について考えると精神が死んでくるのでここらでやめておきますが。Pseudo-Labeling
adversarial validation
アンサンブル
複数モデルをアンサンブルした方が良いぞということ。
こんな感じですかね?まだまだ後から書けそうなことを思いついて、追記するかも知れませんがとりあえずこんな感じで僕の参加記は終わろうと思います。長々見てくれた人がいたらありがとうございました。
余談ですが、今回はてなブログをMarkdown記法で書いてみたのですが書きにくい、かつ読みにくいと感じました。(やっぱり改行の仕様が酷いんだよなMarkdown、何だよ半角スペース二回って)次の記事からははてな記法に戻すと思います。読みにくく感じたらすみません。